Decreasing Hallucinations in RAG Pipelines with Future AGI
Reduce hallucinations in RAG pipelines by benchmarking chunking, retrieval, and chain strategies with Future AGI's evaluation suite.
Objective
This cookbook aims to minimise hallucinations in a typical RAG workflows by carefully assessing and refining key components of the RAG pipeline. The goal is to discover the optimal setting which will yield accurate and context-grounded responses by using Future AGI’s evaluation suite. Using a structured benchmark dataset composed of user questions, retrieved context passages, and model-generated answers, we assess how well different RAG setup utilise provided information to minimise factual inconsistencies.
This includes tuning three core aspects of a RAG pipeline: chunking strategies, retrieval strategies, and chain strategies. And then assessing every single unique combination for its effect on hallucination rates. Ultimately, it aims at a quantitative method to select RAG configurations whose contextual relevance and factual alignment is optimal, contributing to the overall trustworthiness of outcomes from the RAG application.
About The Dataset
We use here a benchmark dataset for the evaluation of the response alignment for RAG workflows. This allows to measure how models use retrieved context to generate relevant responses. The dataset contains the following columns:
- question: The user query that was asked to the language model.
- context: The retrieved text provided to the model to help answer the query.
- answer: The response generated by the model using the given context and question.
Below are a few sample rows from the dataset:
| context | question | answer |
|---|---|---|
| Francisco Rogers found the answer to a search query collar george herbert write my essay constitution research paper ideas definition essay humility … | Who found the answer to a search query collar george herbert essay? | Francisco Rogers found the answer to a search query collar george herbert essay. |
| Game Notes EDM vs BUF Buffalo Sabres (Head Coach: Dan Bylsma) at Edmonton Oilers (Head Coach: Todd McLellan) NHL Game #31, Rogers Place, 2016-10-16 05:00:00PM (GMT -0600) … | Who were the three stars in the NHL game between Buffalo Sabres and Edmonton Oilers? | The three stars were Ryan O’Reilly, Brian Gionta, and Leon Draisaitl. |
Methodology
To systematically reduce hallucinations in RAG workflows, this cookbook adopts a structured evaluation pipeline driven by Future AGI’s automated instrumentation framework. The methodology is centered around three phases: configuration-driven RAG setup, model response generation, and automated evaluation of factual alignment and context adherence.
- Configuration-Driven RAG Setup: The RAG system is parameterised in a configuration file which enables reproducible experimentation for different strategies. These key components include:
- Chunking Strategy: The input document are chunked using either
RecursiveCharacterTextSplitterorCharacterTextSplitter. - Retrieval Strategy: Using FAISS-based vector stores to perform document retrieval via either
similarityormmr(Maximal Marginal Relevance) search modes - Chain Strategy: Feed retrieved documents+input queries into a LangChain-based chain (
stuff,map_reduce,refineormap_rerank) to get final responses via OpenAI’s GPT-4o-mini.
- Chunking Strategy: The input document are chunked using either
- Instrumentation: The evaluation from Future AGI is provided through the
fi_instrumentationSDK. This setup allows evaluation in real-time across the following metrics:- Groundedness: Evaluates whether a response is firmly based on the provided context.
- Context Adherence: Evaluates how well responses stays within the provided context.
- Context Retrieval Quality: Evaluates the quality of the context retrieved for generating a response.
Tip
- Automated Evaluation Execution: A predefined set of queries is executed against each RAG configuration. For each query:
- The RAG pipeline generates a response based on the configured setup.
- Evaluation spans are automatically captured and sent to Future AGI.
- Scores for groundedness, context adherence, and retrieval quality are logged and analysed.
Experimentation
1. Project Structure Overview
project/
├── data.csv # Dataset used in this experiment in CSV format
├── config.yaml # Configuration file defining experiment parameters
└── rag_experiment.py # Main script to run RAG setup and evaluation
2. Configuration File (config.yaml)
Defines all the experiment parameters such as:
- API keys such as Open AI’s and Future AGI’s key
Tip
Click here to access Future AGI API keys - Chunking strategy (
splitter_type,chunk_size) - Retrieval type (
similarity,mmr) - Chain strategy (
map_reduce,stuff,refine,map_rerank) - Evaluation queries for benchmarking hallucination and context relevance
future_agi:
api_key: "API_KEY"
secret_key: "SECRET_KEY"
base_url: "https://api.futureagi.com"
project_name: "Experiment_RAG_Evaluation"
project_version: "RecursiveCharacterTextSplitter_similarity_map_reduce"
openai:
api_key: "OPENAI_API_KEY"
llm_model: "gpt-4o-mini"
llm_temperature: 0.5
embedding_model: "text-embedding-3-small"
# --- Data Loading ---
data:
file_path: "./data.csv"
encoding: "utf-8"
# --- Chunking Strategy ---
chunking:
enabled: true # Set to false to load documents whole (1 doc per CSV row)
# Options: RecursiveCharacterTextSplitter, CharacterTextSplitter
splitter_type: "RecursiveCharacterTextSplitter"
chunk_size: 1000
chunk_overlap: 150
# --- Retrieval Strategy ---
retrieval:
# Options: "similarity", "mmr" (Maximal Marginal Relevance)
search_type: "similarity"
k: 3 # Number of documents to retrieve and pass to the LLM
# --- Chain Strategy ---
chain:
# Options: "stuff", "map_reduce", "refine", "map_rerank"
type: "map_reduce"
return_source_documents: true
# --- Evaluation ---
evaluation:
queries:
- "Who found the answer to a search query collar george herbert essay?"
- "What are some of the potential negative impacts of charity as discussed in the context?"
- "Who were the three stars in the NHL game between Buffalo Sabres and Edmonton Oilers?"
- "What services does Pearl Moving Company in Santa Clarita, 91390 offer?"
- "What are the responsibilities of a Senior Planning Engineer in London, United Kingdom?"3. Installing Required Libraries
To install essential libraries that is required for the experimentation performed in this cookbook for configuration management, model integration and LangChain capabilities.
pip install pyyaml
pip install langchain-openai
pip install langchain-communityTo add tracing and observability capabilities provided by Future AGI to your LangChain applications.
Tip
pip install traceAI-langchain4. Importing Required Libraries
import os
import csv
import yaml
import argparse
import traceback
from langchain_openai import ChatOpenAI
from langchain_core.prompts import PromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_community.document_loaders.csv_loader import CSVLoader
from langchain_community.vectorstores import FAISS
from langchain_openai import OpenAIEmbeddings
from langchain.text_splitter import (
CharacterTextSplitter,
RecursiveCharacterTextSplitter
)
from langchain.chains import RetrievalQA
from traceai_langchain import LangChainInstrumentor
from fi_instrumentation import register
from fi_instrumentation.fi_types import (
EvalName,
EvalSpanKind,
EvalTag,
EvalTagType,
ProjectType
)5. Configuration Loading
Loads settings from a YAML configuration file. These parameters control document loading, chunking strategies, retrieval logic, and model details.
def load_config(config_path: str) -> dict:
try:
with open(config_path, 'r') as f:
config = yaml.safe_load(f)
print(f"Configuration loaded successfully from {config_path}")
return config
except FileNotFoundError:
print(f"Error: Configuration file not found at {config_path}")
exit(1)
except yaml.YAMLError as e:
print(f"Error parsing YAML file {config_path}: {e}")
exit(1)
except Exception as e:
print(f"An unexpected error occurred while loading config: {e}")
exit(1)6. Environment Setup
This sets the Open AI API and Future AGI API keys from the config into environment variables.
def setup_environment(config: dict):
os.environ["FI_API_KEY"] = config['future_agi'].get('api_key')
os.environ["FI_SECRET_KEY"] = config['future_agi'].get('secret_key')
os.environ["OPENAI_API_KEY"] = config['openai'].get('api_key')
os.environ["FI_BASE_URL"] = config['future_agi'].get('base_url', os.environ.get('FI_BASE_URL', 'https://api.futureagi.com'))7. Instrumentation Setup
It is the process of adding tracing to your LLM applications. Tracing helps you monitor critical metrics like cost, latency, and evaluation results.
Where a span represents a single operation within an execution flow, recording input-output data, execution time, and errors, a trace connects multiple spans to represent the full execution flow of a request.
Tip
This experimentation is done to find the best fit of your application for your use case before deploying in production.
Tip
7.1 Setting Up Eval Tags
To quantify performance of each combination of RAG setup, a set of evals according to the use-case are chosen. In this cookbook, since we are dealing with RAG hallucination, so following evals are chosen for evaluation:
- Groundedness:
- Evaluates if response of model is based on the provided context.
- Input Mapping:
output: The generated response from the model.input: The user-provided input to the model.
- Returns a percentage score, where high score Indicate that the
outputis well-grounded in theinput
- Context Adherence:
- Evaluates how well responses stay within the provided context by measuring if the output contains any information not present in the given context.
- Input Mapping:
output: The output response generated by model.context: The context provided to the model.
- Returns a percentage score where a high score Indicate that the output is more contextually consistent.
- Context Retrieval Quality:
- Evaluates the quality of the context retrieved for generating a response.
- Input Mapping:
input: The user-provided input to the model.output: The output response generated by model.context: The context provided to the model.
- Config:
criteria: Description of the criteria for evaluation
- Returns a percentage score, where a high-score Indicate that the context is relevant or sufficient to produce an accurate and coherent output.
Tip
The eval_tags list contains multiple instances of EvalTag. Each EvalTag represents a specific evaluation configuration to be applied during runtime, encapsulating all necessary parameters for the evaluation process.
Parameters of EvalTag :
-
type: Specifies the category of the evaluation tag. In this cookbook,EvalTagType.OBSERVATION_SPANis used. -
value: Defines the kind of operation the evaluation tag is concerned with.EvalSpanKind.LLMindicates that the evaluation targets operations involving Large Language Models.EvalSpanKind.TOOL: For operations involving tools.
-
eval_name: The name of the evaluation to be performed.- For Groundedness Eval,
EvalName.GROUNDEDNESS, - For Context Adherence Eval,
EvalName.CONTEXT_ADHERENCE, - For Context Retrieval Quality,
EvalName.EVAL_CONTEXT_RETRIEVAL_QUALITY
Tip
Click here to get complete list of evals provided by Future AGI - For Groundedness Eval,
-
config: Dictionary for providing specific configurations for the evaluation. An empty dictionary{}means that default configuration parameters will be used.Tip
Click here to learn more about what config is required for corresponding evals -
mapping: This dictionary maps the required inputs for the evaluation to specific attributes of the operation.Tip
Click here to learn more about what inputs are required for corresponding evals -
custom_eval_name: A user-defined name for the specific evaluation instance.
7.2 Setting Up Trace Provider
The trace provider is part of the traceAI ecosystem, which is an OSS package that enables tracing of AI applications and frameworks. It works in conjunction with OpenTelemetry to monitor code executions across different models, frameworks, and vendors.
Tip
To configure a trace_provider, we need to pass following parameters to register function:
project_type: Specifies the type of project. In this cookbook,ProjectType.EXPERIMENTis used since we are experimenting to find the best RAG setup before deploying in production.ProjectType.OBSERVEis used to observe your AI application in production and measure the performance in real-time.project_name: The name of the project. This is dynamically set from a configuration dictionary,config['future_agi']['project_name']- **
project_version_name**:The version name of the project. Similar to project_name, this is also dynamically set from the configuration dictionary,config['future_agi']['project_version'] eval_tags: A list of evaluation tags that define specific evaluations to be applied.
7.3 Setting Up LangChain Instrumentor
This is done to integrate with the LangChain framework for the collection of telemetry data.
Tip
The instrument method is called on the LangChainInstrumentor instance. This method is responsible for setting up the instrumentation of the LangChain framework using the provided tracer_provider.
Putting it all together, below is the function that configures eval_tags, and sets up trace_provider, which is then passed onto LangChainInstrumentor instance.
def setup_instrumentation(config: dict)
eval_tags=[
EvalTag(
type=EvalTagType.OBSERVATION_SPAN,
value=EvalSpanKind.LLM,
eval_name=EvalName.GROUNDEDNESS,
config={},
mapping={
"input": "llm.input_messages.1.message.content",
"output": "llm.output_messages.0.message.content"
},
custom_eval_name="Groundedness"
),
EvalTag(
type=EvalTagType.OBSERVATION_SPAN,
value=EvalSpanKind.LLM,
eval_name=EvalName.CONTEXT_ADHERENCE,
config={},
mapping={
"context": "llm.input_messages.0.message.content",
"output": "llm.output_messages.0.message.content"
},
custom_eval_name="Context_Adherence"
),
EvalTag(
type=EvalTagType.OBSERVATION_SPAN,
value=EvalSpanKind.LLM,
eval_name=EvalName.EVAL_CONTEXT_RETRIEVAL_QUALITY,
config={
"criteria": "Evaluate if the context is relevant and sufficient to support the output."
},
mapping={
"input": "llm.input_messages.1.message.content",
"output": "llm.output_messages.0.message.content",
"context": "llm.input_messages.0.message.content"
},
custom_eval_name="Context_Retrieval_Quality"
)
]
trace_provider = register(
project_type=ProjectType.EXPERIMENT,
project_name=config['future_agi']['project_name'],
project_version_name=config['future_agi']['project_version'],
eval_tags=eval_tags
)
LangChainInstrumentor().instrument(tracer_provider=trace_provider)
print(f"FutureAGI instrumentation setup for Project: {config['future_agi']['project_name']}, Version: {config['future_agi']['project_version']}")
8. RAG Setup
It reads data, chunks documents, creates embeddings, indexes them using FAISS vector database, and then builds a LangChain-powered RetrievalQA chain.
def setup_rag(config: dict):
data_config = config['data']
chunking_config = config['chunking']
retrieval_config = config['retrieval']
chain_config = config['chain']
openai_config = config['openai']
print(f"--- RAG Setup using Configuration ---")
print(f"Data Path: {data_config['file_path']}")
print(f"Chunking Enabled: {chunking_config['enabled']}")
if chunking_config['enabled']:
print(f"Chunker: {chunking_config['splitter_type']}, Size: {chunking_config['chunk_size']}, Overlap: {chunking_config['chunk_overlap']}")
print(f"Retrieval Type: {retrieval_config['search_type']}, k: {retrieval_config['k']}")
if retrieval_config['search_type'] == 'mmr':
print(f"MMR Fetch K: {retrieval_config.get('fetch_k', 20)}, Lambda: {retrieval_config.get('lambda_mult', 0.5)}")
print(f"Chain Type: {chain_config['type']}")
print(f"LLM Model: {openai_config['llm_model']}, Temp: {openai_config['llm_temperature']}")
print(f"Embedding Model: {openai_config.get('embedding_model', 'Default')}")
print("-" * 30)
try:
# 1. Load Documents
loader_args = {
"file_path": data_config['file_path'],
"encoding": data_config['encoding'],
}
if data_config.get('source_column'):
loader_args['source_column'] = data_config['source_column']
if data_config.get('metadata_columns'):
loader_args['csv_args'] = {'fieldnames': data_config['metadata_columns']}
loader = CSVLoader(**loader_args)
documents = loader.load()
print(f"Loaded {len(documents)} documents.")
if not documents:
print(f"No documents loaded. Check file content and CSVLoader configuration.")
return None
# 2. Chunk Documents (if enabled)
if chunking_config['enabled']:
splitter_type = chunking_config['splitter_type']
if splitter_type == "RecursiveCharacterTextSplitter":
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=chunking_config['chunk_size'],
chunk_overlap=chunking_config['chunk_overlap'],
length_function=len,
add_start_index=True,
)
elif splitter_type == "CharacterTextSplitter":
text_splitter = CharacterTextSplitter(
separator="\n\n",
chunk_size=chunking_config['chunk_size'],
chunk_overlap=chunking_config['chunk_overlap'],
length_function=len,
)
else:
print(f"Warning: Unknown splitter_type '{splitter_type}'. Defaulting to RecursiveCharacterTextSplitter.")
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=chunking_config['chunk_size'],
chunk_overlap=chunking_config['chunk_overlap']
)
docs_to_index = text_splitter.split_documents(documents)
print(f"Split into {len(docs_to_index)} chunks.")
else:
docs_to_index = documents
print("Chunking disabled, indexing whole documents.")
# 3. Create Embeddings
embedding_model_name = openai_config.get('embedding_model')
if embedding_model_name:
embeddings = OpenAIEmbeddings(model=embedding_model_name)
else:
embeddings = OpenAIEmbeddings()
# 4. Create Vector Store
print("Creating vector store...")
vectorstore = FAISS.from_documents(docs_to_index, embeddings)
print("Vector store created successfully.")
# 5. Create Retriever
retriever_kwargs = {"k": retrieval_config['k']}
search_type = retrieval_config['search_type']
if search_type == "mmr":
retriever_kwargs['fetch_k'] = retrieval_config.get('fetch_k', 20)
retriever_kwargs['lambda_mult'] = retrieval_config.get('lambda_mult', 0.5)
retriever = vectorstore.as_retriever(
search_type=search_type,
search_kwargs=retriever_kwargs
)
# 6. Create LLM
llm = ChatOpenAI(
temperature=openai_config['llm_temperature'],
model=openai_config['llm_model']
)
# 7. Create RetrievalQA Chain
rag_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type=chain_config['type'],
retriever=retriever,
return_source_documents=chain_config['return_source_documents']
)
print("RAG chain setup complete.")
return rag_chain
except ValueError as ve:
print(f"ValueError during RAG setup: {ve}")
if "got an unexpected keyword argument 'fieldnames'" in str(ve):
print("Hint: Check 'metadata_columns' in config.yaml. CSVLoader might expect them differently or they might not exist.")
elif "must have a source_column" in str(ve):
print("Hint: Check 'source_column' in config.yaml. It might be missing or incorrect.")
else:
print("This might relate to CSV column names specified in config.yaml (source_column, metadata_columns) not matching data.csv.")
traceback.print_exc()
return None
except Exception as e:
print(f"Error setting up RAG system: {str(e)}")
traceback.print_exc()
return None9. Query Processing
Runs a single query through the RAG pipeline and retrieves the model’s answer.
def process_query(rag_chain, query: str, data_file_path: str):
if rag_chain is None:
return f"Sorry, the knowledge base from '{data_file_path}' could not be loaded. RAG chain is None."
try:
print(f"Invoking RAG chain for query: '{query}'")
result = rag_chain.invoke({"query": query})
response = result.get("result", "No answer could be generated based on the documents.")
if rag_chain.return_source_documents:
source_docs = result.get("source_documents", [])
print(f"Retrieved {len(source_docs)} source documents for the answer.")
return response
except Exception as e:
print(f"Error processing RAG query: {str(e)}")
traceback.print_exc()
return f"Sorry, I encountered an error during retrieval or generation: {str(e)}"
10. Evaluation Execution
It sets up the RAG pipeline and loads queries from configuration file. For each query, it Invokes the pipeline and sends data to Future AGI for scoring.
def run_evaluation_queries(config: dict):
print("\n--- Initializing RAG based on Configuration ---")
rag_chain = setup_rag(config)
if rag_chain is None:
print("\n--- RAG Setup Failed. Cannot run evaluation queries. Please check errors above. ---")
return {}
print("\n--- Starting RAG Evaluation Queries ---")
queries = config['evaluation']['queries']
data_file_path = config['data']['file_path']
if not queries or any("[Your Column Name]" in q for q in queries):
print("\n*** WARNING: Please replace placeholder queries in config.yaml under 'evaluation.queries'")
print("*** with questions relevant to your specific data.csv file for meaningful evaluation! ***\n")
results = {}
for i, query in enumerate(queries):
print(f"\n--- Query {i+1}/{len(queries)} ---")
print(f"Query: {query}")
response = process_query(rag_chain, query, data_file_path)
print(f"Response: {response}")
results[query] = response
print("-" * 20)
print("\n--- RAG Evaluation Queries Finished ---")
print("Check the FutureAGI platform for traces and evaluation results.")
print(f"Project: {config['future_agi']['project_name']}, Version: {config['future_agi']['project_version']}")
return results11. Main Function
It parses command-line arguments, loads the config, sets up environment variables and instrumentation, and runs the full evaluation process.
if __name__ == "__main__":
parser = argparse.ArgumentParser(description="Run RAG evaluation with configuration from a YAML file.")
parser.add_argument(
"-c", "--config",
default="config.yaml",
help="Path to the YAML configuration file (default: config.yaml)"
)
args = parser.parse_args()
# Load Configuration
config = load_config(args.config)
# Setup Environment (API Keys etc.)
setup_environment(config)
# Setup FutureAGI Instrumentation
setup_instrumentation(config)
# Run Evaluation
run_evaluation_queries(config)
print("\nScript finished.")Result
Future AGI’s automated scoring framework was used to assess each experimental run to establish which RAG configuration was the most effective. The evaluation included both quality metrics — including groundedness, context correctness, and retrieval quality — as well as system metrics like cost and latency. A weighted preference model to reflect real-world tradeoffs between performance and efficiency was employed to rank the output.
Inside the ‘Choose Winner’ option provided in top right corner of All Runs, the evaluation sliders were positioned to place higher value on model accuracy than operational efficiency. Weights were assigned as follows:
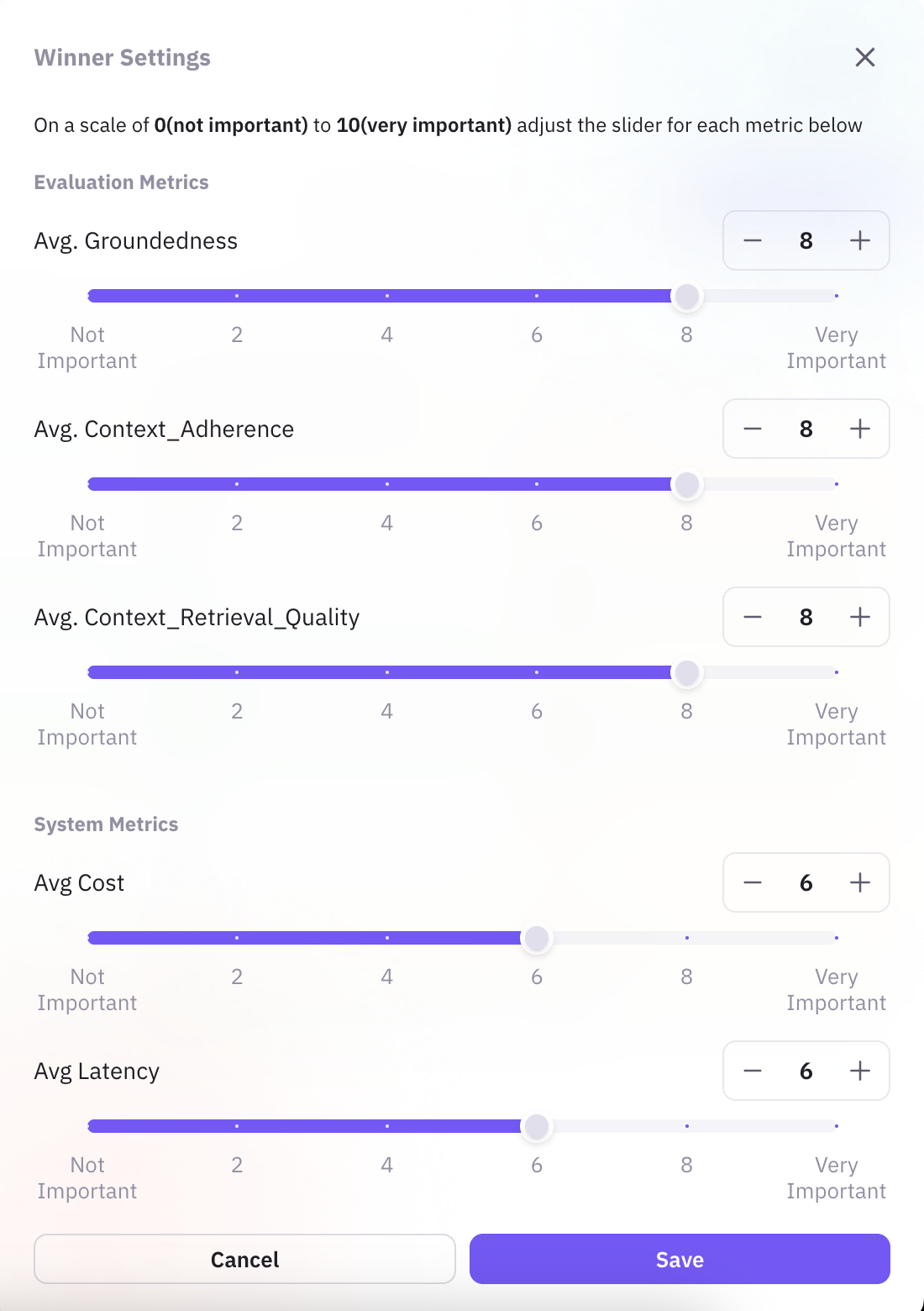
This setup prioritises accuracy and context in alignment at a reasonable cost in keep time and responsiveness.
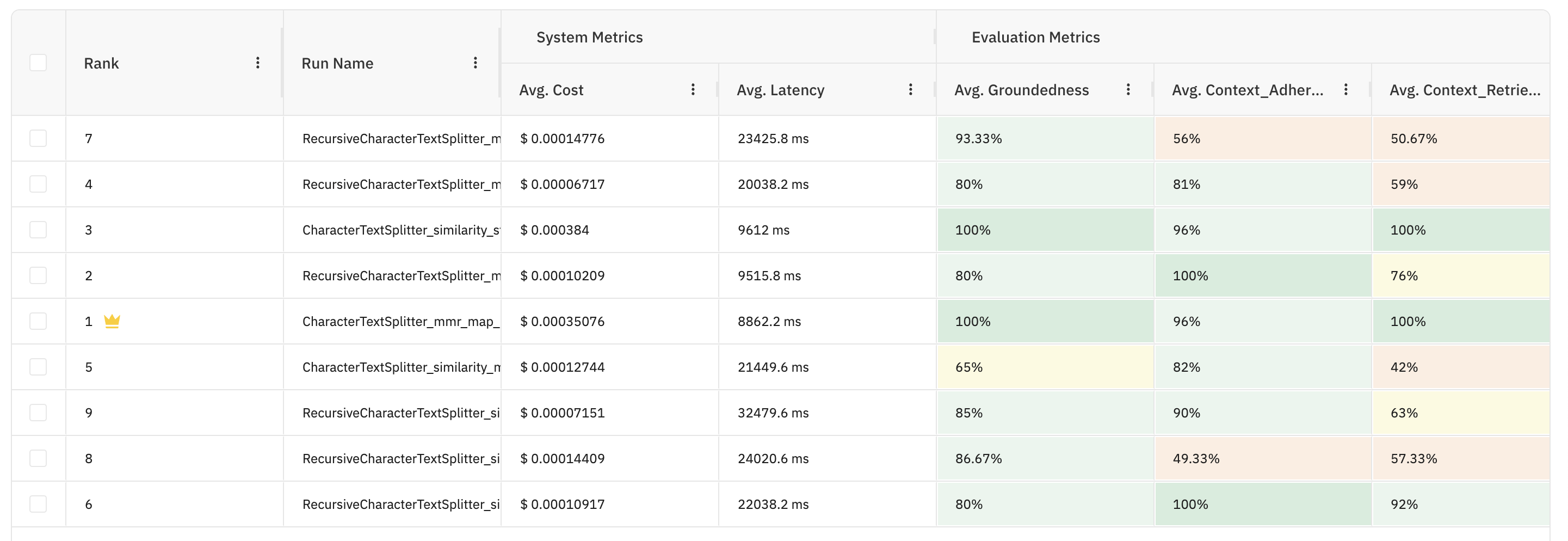
The winner configuration was CharacterTextSplitter_mmr_map_rerank, which combines chatacter-based chunking, MMR (Maximal Marginal Relevance) retrieval and a map-rerank generation. This approach provides a solid trade-off between reliability and efficiency of resources, making it a good fit for production-level RAG pipelines where hallucination minimisation is of concern.
Frequently Asked Questions (FAQs)
-
Will I be able to re-use this evaluation setup for other RAG use cases or datasets?
Yes. The evaluation pipeline described in this blog is configuration based and task agnostic. The instrumentation and metric setup you have applies to any RAG dataset.
-
Will I require labeled data in order to evaluate the hallucinations when using Future AGI?
No, future AGI does model-based evaluation, it rates your outputs with AI evaluators without needing labeled ground truth answers beforehand. This enables rapid, scalable testing across configurations without the manual annotation burden.
-
I am using a different framework for my RAG application. Can I still use Future AGI for evaluation purposes?
Yes. It is compatible with a variety of frameworks via automatic tracing and SDK integrations, such as LangChain, Haystack, DSPy, LlamaIndex, Instructor, Crew AI, and others. With little to no setup, most major RAG stacks can have their evaluations instrumented.
-
How can I be sure my RAG pipeline isn’t hallucinating?
One way to identify hallucinations is to check if the responses generated by the model are directly supported by the context that is retrieved. This way, you will be able to measure factual alignment with automated metrics like Groundedness and Context Adherence instead of human reviewers.
-
Can I create custom evaluations tailored to my RAG use case in Future AGI?
Yes. The Deterministic Eval template in Future AGI supports custom evaluations (Click here to learn more about deterministic eval). This lets you apply stringent criteria to your RAG outputs minimising variability.
Ready to Reduce Hallucinations in Your RAG Applications?
Start evaluating your RAG workflows with confidence using Future AGI’s automated, no-label-required evaluation framework. Future AGI provides the tools you need to systematically reduce hallucination.
Questions & Discussion