1. Introduction
As LLMs are becoming integral to enterprise applications, one of the most valuable and challenging use cases is question-answering over internal documents such as PDFs. Retrieval-Augmented Generation (RAG) is the widely-used solution to power these systems, offering a scalable way to inject real-time context into LLMs without retraining. However, even well-designed RAG pipelines frequently fail in subtle, high-impact ways such as the wrong chunks are retrieved, filters are misapplied, embeddings mismatch, or the model hallucinates entirely. Without visibility into the retrieval step or a mechanism to evaluate generated answers at scale, these systems quickly degrade in quality and thus leading to silent errors, eroded trust, and high operational cost.
This is where MongoDB Atlas and Future AGI come in. MongoDB Atlas offers a unified platform that combines structured document storage, full-text indexing, and vector search in a single developer-friendly environment. Allowing you to combine semantic similarity with metadata filtering and keyword matching, all while managing your data securely and at scale. This makes it easy to build retrieval layers that are not only powerful, but also maintainable and aligned with real-world data access needs.
On top of this, Future AGI brings the missing layer of observability, evaluation and optimisation to the RAG systems. It instruments the entire LLM request pipeline by capturing structured traces with rich metadata. Each response is scored using built-in and custom evals that assess the pipeline based on the business use-case. Developers and Business teams gain immediate insight into where the system is underperforming, why it failed, and how to fix it. With dashboards, alerts, and span-level telemetry, Future AGI turns opaque LLM pipelines into observable, testable systems that can be reliably operated in production.
This cookbook walks through how to integrate MongoDB Atlas and Future AGI to build a robust PDF-based RAG application. By the end, you’ll have a framework that not only generates useful answers but one that you can explain, monitor, and continuously improve with confidence.
2. Methodology
This cookbook implements a document-grounded question-answering pipeline using MongoDB Atlas for vector-based retrieval and Future AGI for span-level observability and evaluations. The goal is to enable users to upload PDF documents and interact with a chatbot that generates answers grounded in the uploaded content, while making the system’s internal behavior observable and traceable.
The workflow begins with PDF ingestion via a Gradio-based user interface. Uploaded files are parsed using LangChain. Then the chunks are created from this extracted text. Each text chunk is then embedded using OpenAI’s model. These vector representations, along with their source text and metadata, are stored in MongoDB Atlas. The system uses MongoDB Atlas Vector Search as both a persistent database and a vector index, supporting cosine similarity for efficient nearest-neighbor retrieval. It supports both the latest and legacy index schemas, allowing for broad compatibility across environments. Index creation is handled programmatically, and embedding dimensions are auto-detected to ensure alignment with the embedding model.
 Fig 1. Methodology for integrating Future AGI’s observability into MongoDB-based RAG application
When a user submits a natural language question, the system retrieves the top-K most similar chunks using vector search. These chunks are included in a structured prompt along with the original query and passed to an OpenAI model via LangChain’s RetrievalQA chain. The model generates a response grounded in the retrieved context. Depending on configuration, the assistant can operate in a strict mode, where responses must rely solely on context, or a fallback mode that allows the use of general knowledge with appropriate disclaimers.
To support observability and evaluation, we integrates Future AGI’s
Fig 1. Methodology for integrating Future AGI’s observability into MongoDB-based RAG application
When a user submits a natural language question, the system retrieves the top-K most similar chunks using vector search. These chunks are included in a structured prompt along with the original query and passed to an OpenAI model via LangChain’s RetrievalQA chain. The model generates a response grounded in the retrieved context. Depending on configuration, the assistant can operate in a strict mode, where responses must rely solely on context, or a fallback mode that allows the use of general knowledge with appropriate disclaimers.
To support observability and evaluation, we integrates Future AGI’s traceai-langchain instrumentation. Each user interaction produces a detailed trace that captures embeddings, retrieval results, prompt construction, and model outputs. These traces help developers understand how answers are generated, identify potential failure points such as retrieval errors or hallucinations, and monitor system latency. This observability layer makes the assistant not only functional but also transparent and easier to maintain.
The entire system is surfaced through a simple Gradio interface. After uploading and processing documents, users can ask questions and receive contextual answers along with referenced file names and page numbers. This end-to-end design provides a practical and extensible foundation for building explainable RAG applications.
3. Why Observability and Evaluation Matter in RAGs
As RAGs transition from experimentation to production, the core challenge shifts from generating plausible answers to ensuring their reliability, traceability, and correctness. Unlike traditional software systems where monitoring infrastructure metrics such as API uptime or memory consumption can capture most failure modes but LLM-powered applications introduce a new class of risks.
These systems may appear operational at the infrastructure level while silently failing at the semantic level by retrieving irrelevant context, introducing hallucinations, or producing incomplete or misleading answers. In production environments, such failures can erode user trust, cause compliance violations, and degrade product quality over time.
This is why observability and evaluation are critical pillars for building reliable RAG applications. Observability helps teams understand what’s happening inside a RAG pipeline. Future AGI brings this visibility by instrumenting every step in a request’s lifecycle using spans and traces.
A span represents a single operation like embedding a query, searching a vector store, or generating a response and includes metadata such as inputs, outputs, latency, and errors.
A trace connects all related spans for a given user request, forming a full picture of how the system processed that request.
4. Instrumenting LangChain Framework
Future AGI builds on OpenTelemetry (OTel), the industry-standard open-source observability framework. OTel ensures traces are vendor-neutral, scalable, and exportable across monitoring backends. But OTel is infrastructure-centric. It understands function calls, API latencies, and database queries but not embeddings, prompts, or hallucinations.
To bridge this gap, Future AGI developed traceAI, an open-source package to enable standardised tracing of AI applications and frameworks. traceAI integrates seamlessly with OTel and provides auto-instrumentation packages for popular frameworks such as LangChain. With traceAI-langchain, every LangChain operation is automatically traced with meaningful attributes.
from fi_instrumentation import register
from fi_instrumentation.fi_types import ProjectType
trace_provider = register(
project_type=ProjectType.OBSERVE,
project_name="langchain_mongodb_project",
)
LangChainInstrumentor().instrument(tracer_provider=trace_provider)
register() sets up an OpenTelemetry tracer that ships spans to Future AGI.LangChainInstrumentor().instrument() auto-instruments LangChain so you get more AI-aware spans (Embedding, Retriever, LLM, Index build) with rich attributes (model name, token usage, prompt, chunk metadata, latencies, errors).
Click here to learn more about auto-instrumention
5. Setting up MongoDB Atlas
This cookbook is using MongoDB Atlas as both the document storage layer and the vector search engine. All extracted chunks from uploaded PDFs, along with their vector embeddings and metadata, are stored in a single MongoDB collection. During startup, the application connects to the specified Atlas cluster and ensures that the collection is available and accessible. It also checks for proper authentication and connection status to help prevent common misconfigurations.
A key step in setting up vector search is ensuring that MongoDB Atlas knows the exact size of the vectors (dimensions) it will be indexing. Each embedding model produces vectors of a specific length. To avoid hardcoding this and risking mismatches when switching models, the code dynamically detects the dimension at runtime by embedding a dummy input using langchain’s embed_query() method on OpenAIEmbeddings package. This allows the application to query the model for a real vector and extract its true shape.
With the correct dimension in hand, the application proceeds to configure the search index in Atlas. It first tries the modern schema (knnVector) supported by MongoDB’s native vector search. If that isn’t available (e.g. on older clusters), it falls back to a legacy format (vector). Both configurations uses cosine similarity, which is suitable for semantic search tasks like document retrieval. This two-step approach ensures that the system remains compatible, robust, and aligned with whatever embedding model is in use without manual tweaks.
6. Ingesting PDFs and Handling Queries
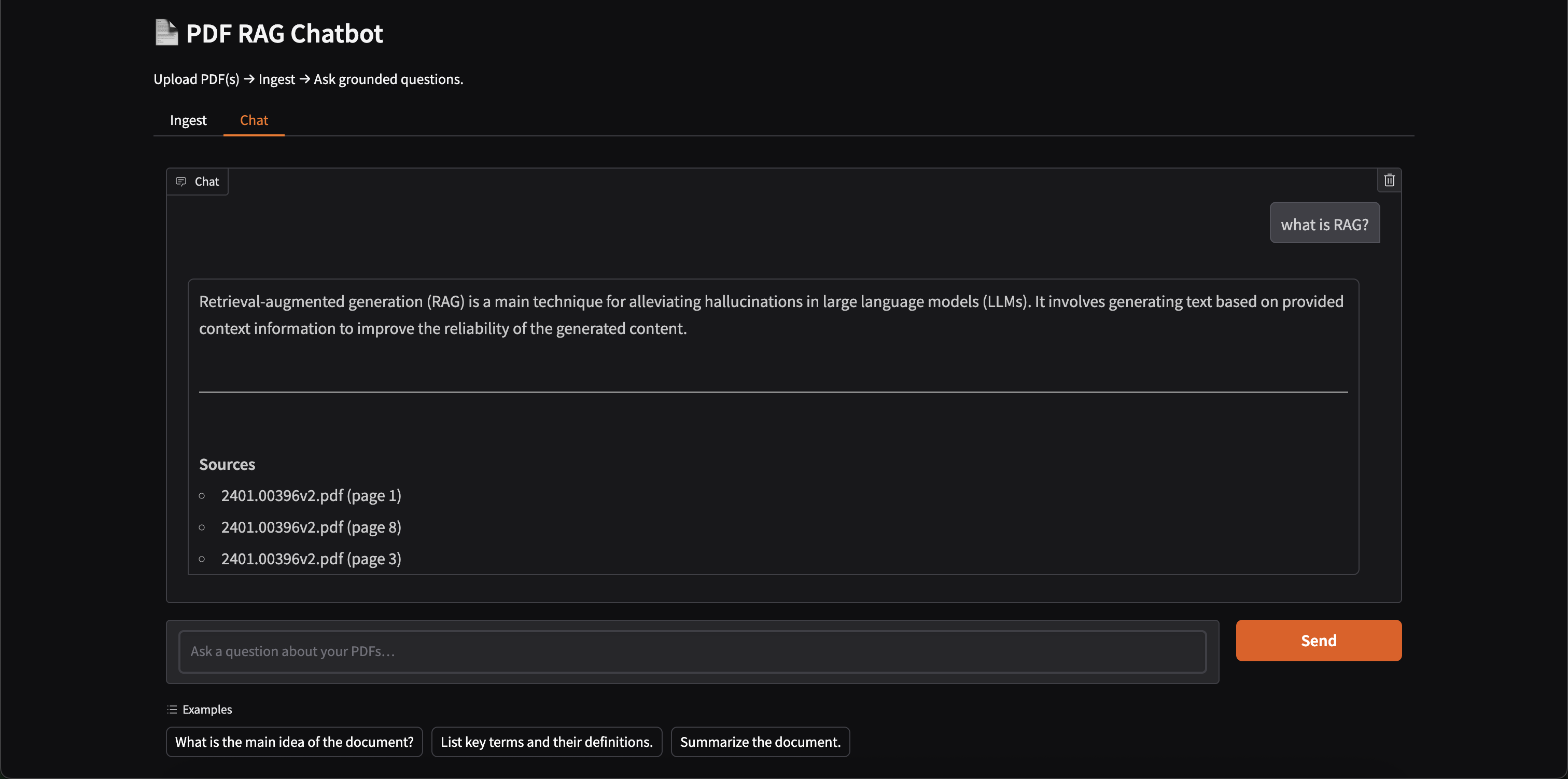 Fig 2. PDF-ingested chatbot with Gradio UI
When a user uploads PDF documents, the RAG application processes them in several stages to prepare for efficient and accurate retrieval. First, the PDF content is extracted using
Fig 2. PDF-ingested chatbot with Gradio UI
When a user uploads PDF documents, the RAG application processes them in several stages to prepare for efficient and accurate retrieval. First, the PDF content is extracted using PyPDFLoader. Since language models perform better with shorter inputs, the full text is split into overlapping chunks using RecursiveCharacterTextSplitter. These chunks help preserve context across boundaries while keeping the input size manageable.
Each chunk is then embedded using the OpenAI’s text-embedding-3-small embedding model. These embedding vectors, along with the original chunk text and relevant metadata, are stored in MongoDB Atlas.
When a user submits a question, the system embeds the query in the same vector space and performs a similarity search against the stored embeddings. The most relevant chunks (here we are using top 6 relevant chunks) are retrieved and passed to RetrievalQA chain. This chain generates an answer using the retrieved context and a structured prompt that keeps responses grounded in the source material.
7. Evaluation
7.1 Using Built-in Evals
Instrumenting the chatbot gives you traces. But raw traces are only half the story. To ensure reliability, you also need evaluations. Future AGI lets you attach evaluation tasks from the dashboard/UI directly to spans in your pipeline. For a PDF-based RAG chatbot, the most relevant evaluations include:
- Task Completion: Did the response fully solve what the user asked for? This ensures answers are not partial or evasive.
- Detect Hallucination: Did the model introduce unsupported or fabricated facts? This prevents users from being misled.
- Context Relevance: Were the retrieved chunks the right ones to answer the query? This checks if retrieval is working properly.
- Context Adherence: Did the model stay within retrieved context and avoid drifting into unrelated information? This reinforces factual consistency.
- Chunk Utilization: Quantifies how effectively the assistant incorporated retrieved context into its response.
- Chunk Attribution: Validates whether the response referenced the retrieved chunks at all.
Click here to learn more about all the builtin evals Future AGI provides
These builtin evaluators provide strong coverage of the core failure modes in RAG pipelines: failing to answer the task, hallucinating unsupported facts, retrieving irrelevant context, ignoring retrieved content, or failing to attribute sources. Running them ensures a baseline level of quality monitoring across the system.
7.2 Need for Custom Evals
However, no two enterprises share identical requirements. Builtin evaluations are general-purpose, but in many cases, domain-specific validation is needed. For example, a financial assistant may need to verify regulatory compliance, while a medical assistant must ensure responses align with clinical guidelines. This is where custom evaluations become essential.
Future AGI supports creating custom evaluations that allow teams to define their own rules, scoring mechanisms, and validation logic. Custom evaluators are particularly useful when:
- Standard checks are not enough to capture domain-specific risks.
- Outputs must conform to strict business rules or regulatory frameworks.
- Multi-factor scoring or weighted metrics are required.
- You want guarantees about output format, citation correctness, or evidence alignment beyond generic grounding tests.
Click here to learn more about creating and using custom evals in Future AGI
We built a custom evaluation called reference_verification to ensure strict fidelity between responses and retrieved context. Unlike general hallucination detection, which flags unsupported content, this evaluation enforces a stronger rule: every claim must be traceable to retrieved chunks. This is crucial for document-grounded workflows like our PDF chatbot, where users expect not just hallucination-free answers but also correctly cited evidence.
7.3 Setting Up Evals
In the Future AGI dashboard, we define evals as tasks and attach them to the appropriate span types as shown in Fig 3.
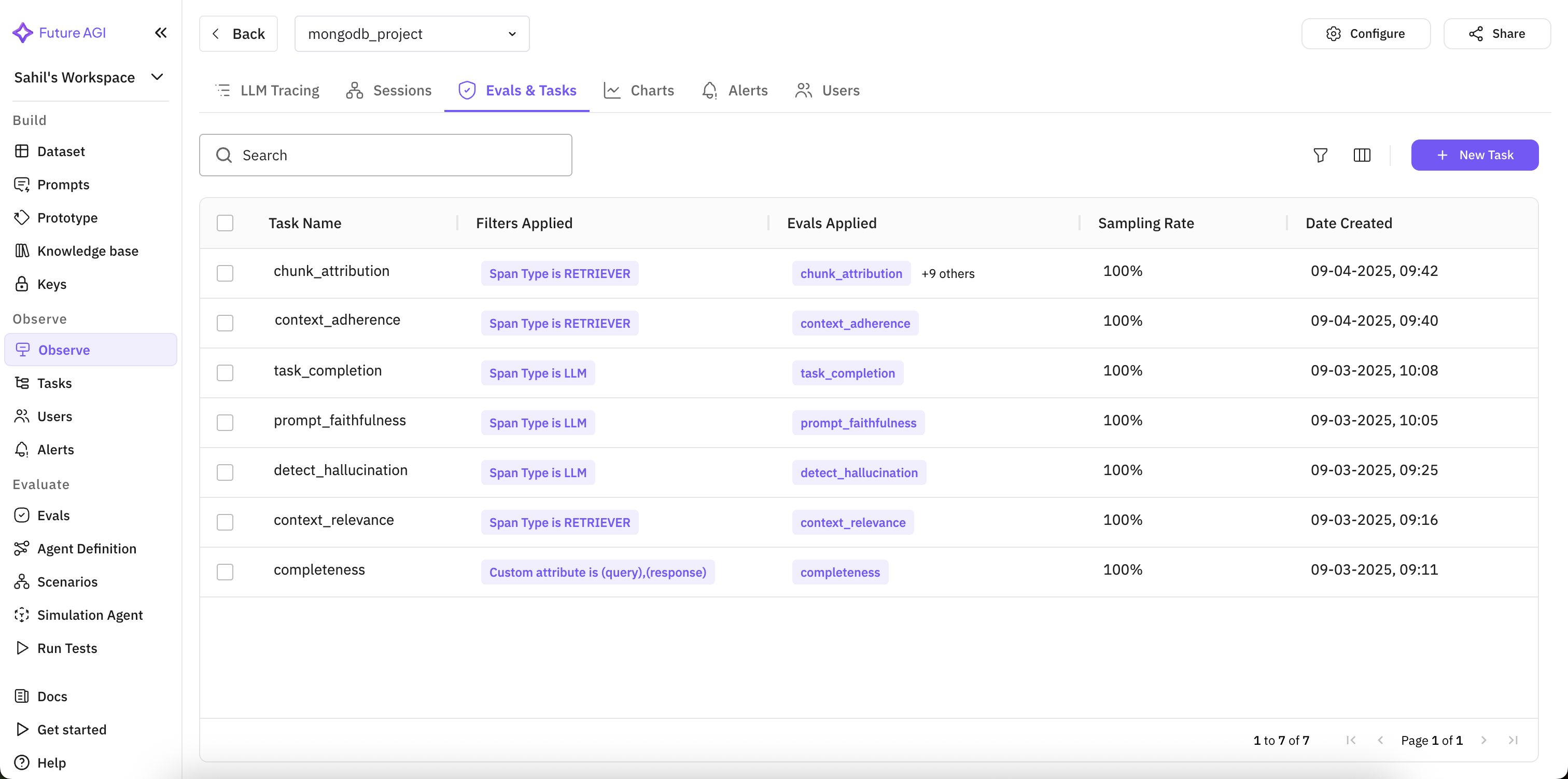 Fig 3. Setting up evals at span level
This way, each span in a trace is automatically evaluated as soon as it’s generated. When a user asks a question, the trace view shows every operation in Fig 4. On the left you can see the hierarchy of spans (embedding, retrieval, generation). On the right you can see the inputs and outputs (query + generated response). Bottom panel shows the eval results applied span-by-span.
Fig 3. Setting up evals at span level
This way, each span in a trace is automatically evaluated as soon as it’s generated. When a user asks a question, the trace view shows every operation in Fig 4. On the left you can see the hierarchy of spans (embedding, retrieval, generation). On the right you can see the inputs and outputs (query + generated response). Bottom panel shows the eval results applied span-by-span.
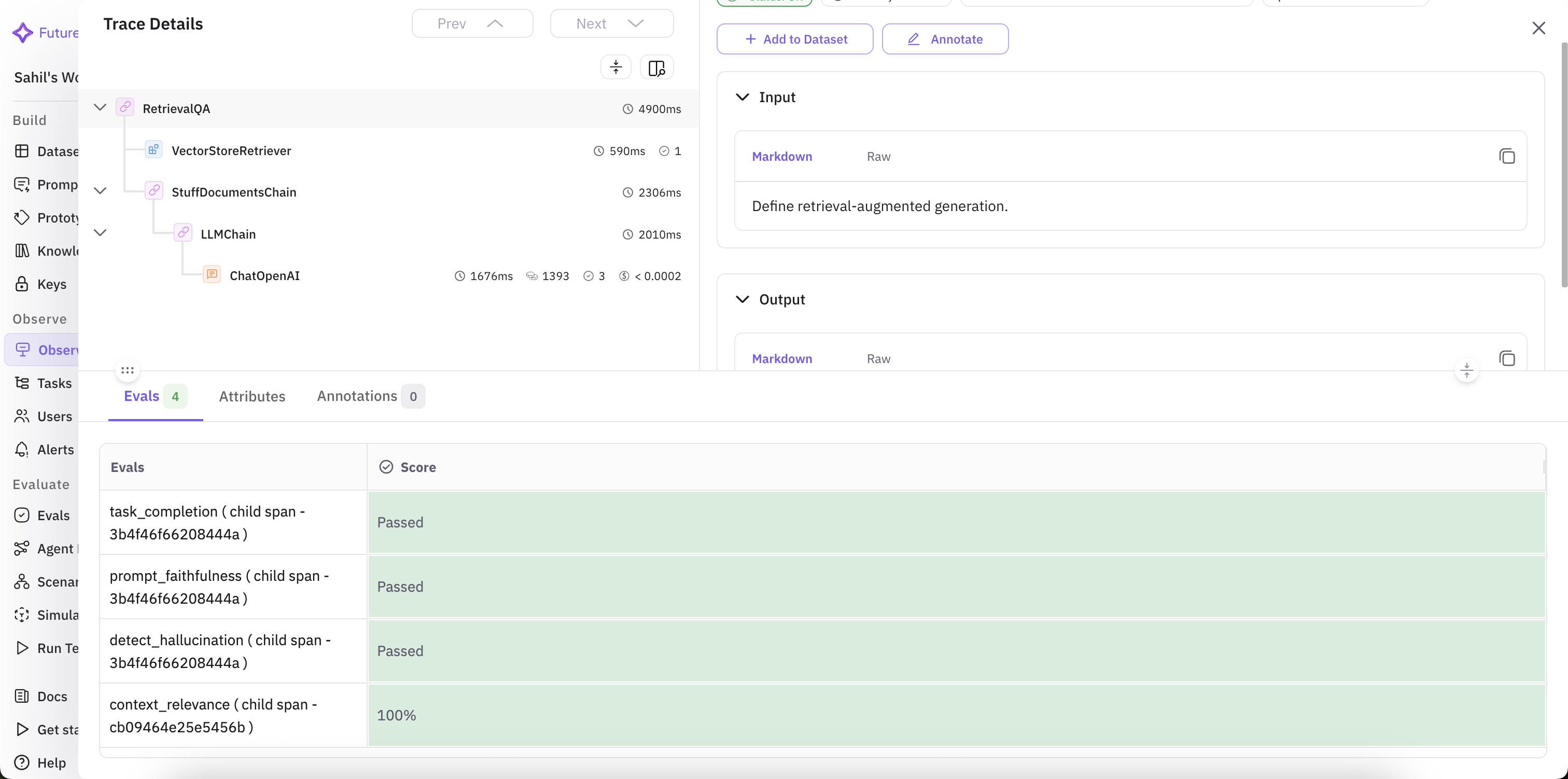 Fig 4. Trace-level details of chatbot
Fig 4. Trace-level details of chatbot
7.4 Key Insights
The evaluation results provide a clear insight of the system’s reliability across all stages of the RAG pipeline:
- The task was completed successfully, confirming that the assistant’s response directly addressed the user’s query.
- Additionally, detect_hallucination passing shows the assistant did not fabricate any information, reinforcing factual accuracy.
- Most notably, context_relevance scored 100%, meaning the retriever surfaced highly relevant chunks for the question, ensuring the model had the right information to work with.
Together, these scores suggest a well-calibrated pipeline where each component of retrieval, generation, and grounding, all operates in alignment, delivering trustworthy and instruction-following responses.
7.5 Dashboard
Future AGI provides a comprehensive dashboard, as shown in figure 5, to visually analyse the eval results along with system metrics such as latency, cost, etc for comparing the performance of your application visually.
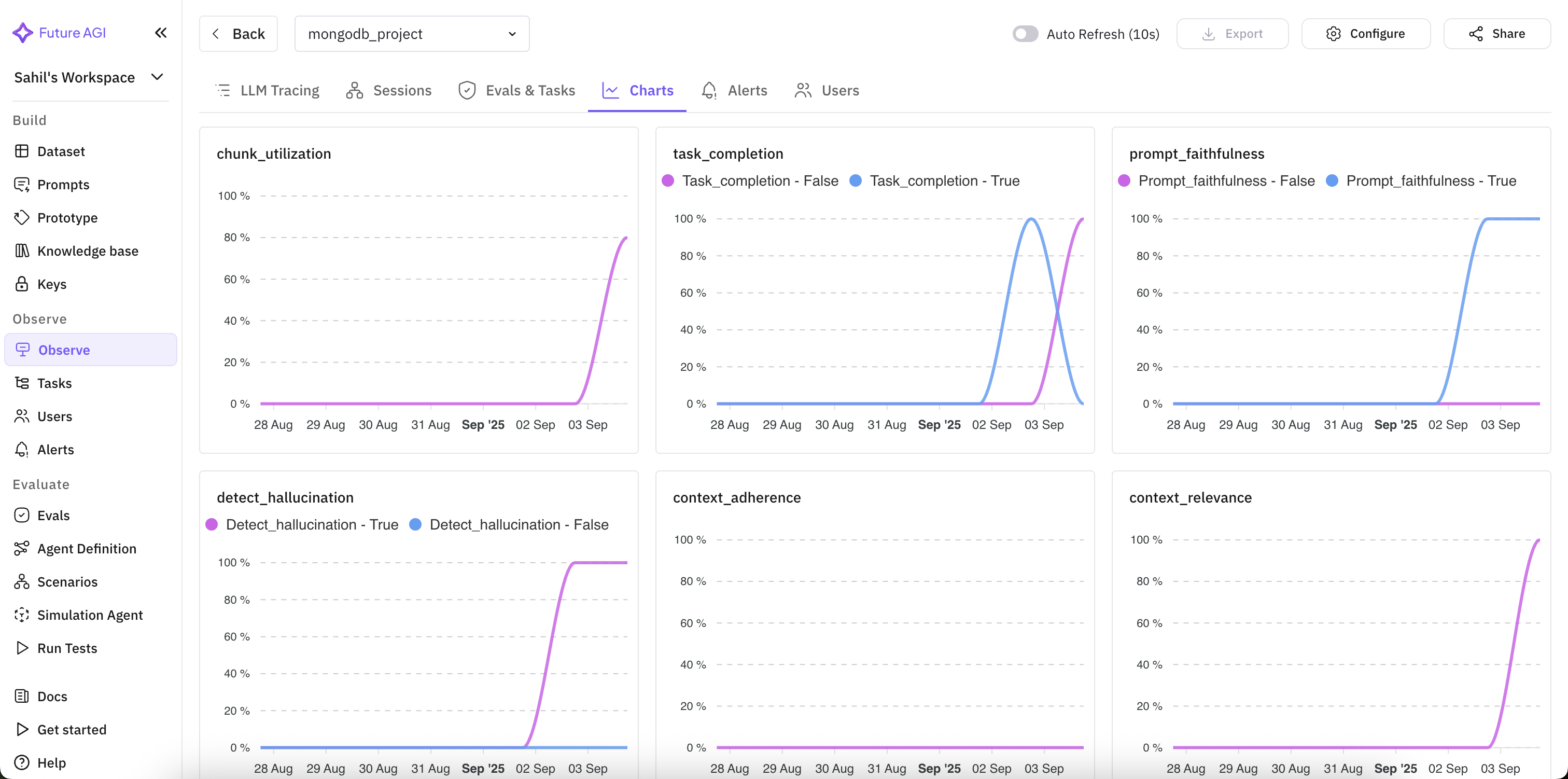 Fig 5. Charts of eval metrics and system metrics
These evaluations reveal that while the chatbot can complete tasks and avoid hallucinations, there is room for improvement in how context is retrieved and adhered to. High task completion and no hallucination confirm reliability at the generation stage, but weaker relevance and adherence scores highlight weaknesses in retrieval. Addressing these gaps through better chunking, reranking, or retriever tuning can significantly improve grounding quality and user trust.
Fig 5. Charts of eval metrics and system metrics
These evaluations reveal that while the chatbot can complete tasks and avoid hallucinations, there is room for improvement in how context is retrieved and adhered to. High task completion and no hallucination confirm reliability at the generation stage, but weaker relevance and adherence scores highlight weaknesses in retrieval. Addressing these gaps through better chunking, reranking, or retriever tuning can significantly improve grounding quality and user trust.
7.6 Need for Continuous Evaluation
What makes this approach powerful is that evaluations run continuously and automatically across every user interaction. The system generates real-time quality signals that reflect how the pipeline performs under actual workloads. For example, a sudden dip in context relevance immediately points developers to retrieval as the root cause, while a drop in context adherence highlights drift during synthesis.
In production environments, this continuous scoring becomes more than diagnostic; it forms the foundation for proactive monitoring. Once thresholds are defined, for example, hallucination must remain below x%, or relevance must stay above y%, Future AGI can automatically trigger alerts the moment performance begins to degrade. Instead of discovering weeks later that users were served incomplete or poorly grounded answers, teams receive real-time Slack/email notifications and can intervene before quality issues reach end users.
7.7 Setting Up Alerts
Figure 6 below shows how an alert rule can be created directly from evaluation metrics. Here, the developer selects a metric they want to set alert on (e.g., token usage or context relevance), then defines an interval for monitoring, and sets thresholds that represent acceptable performance. Filters can further refine conditions to monitor specific spans, datasets, or user cohorts. This ensures that alerts are tuned to operational and business priorities rather than being generic warnings.
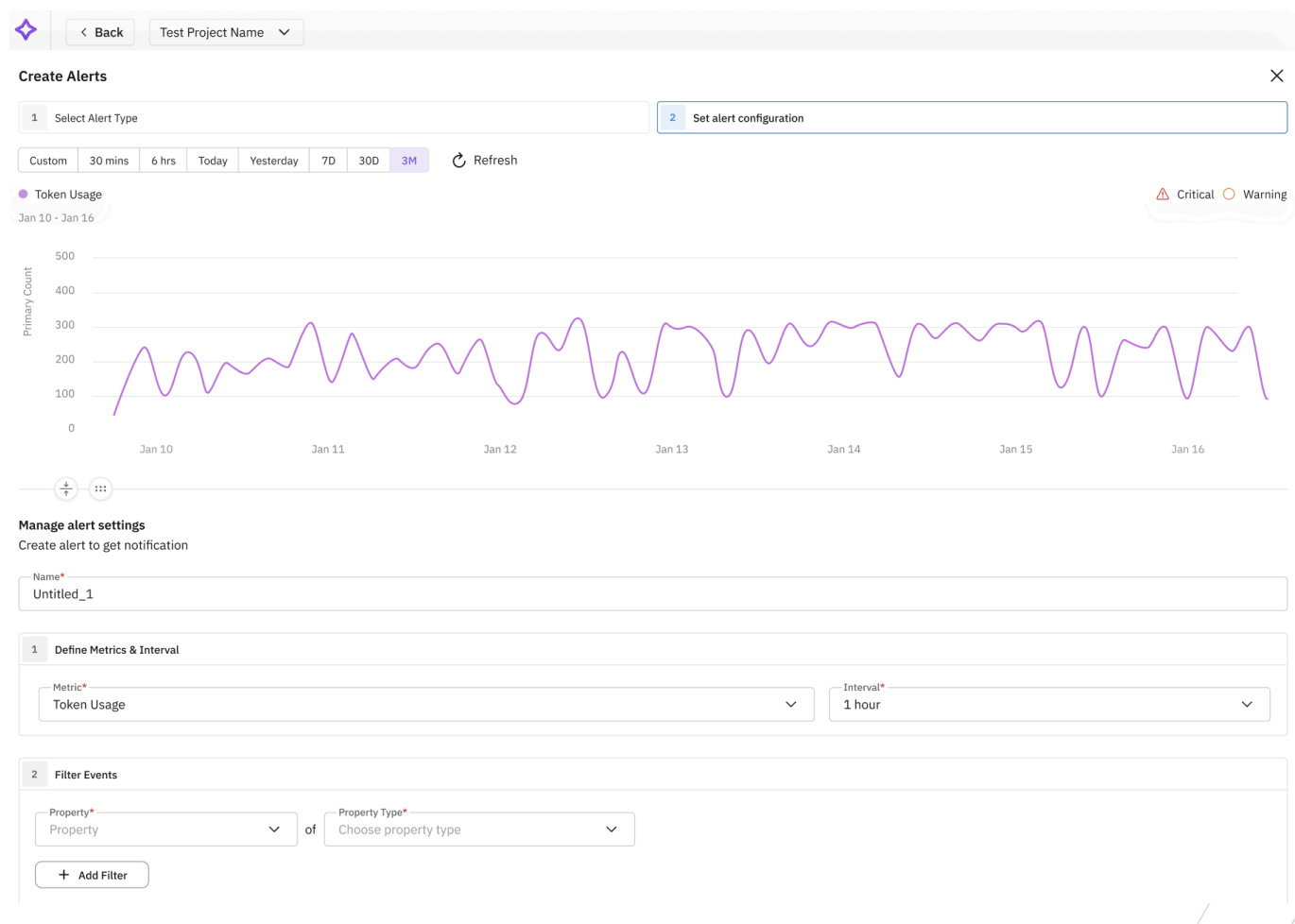 Fig 6. Creating alert rule
Once active, alerts appear in a centralised alerts dashboard, shown in Figure 7. This dashboard consolidates triggered alerts across projects, classifying them by type (e.g., API failures, credit exhaustion, low context relevance), along with the status (Healthy vs Triggered), and time last triggered. Developers can immediately see which parts of the pipeline require attention, mute or resolve alerts, and review historical patterns to detect recurring issues.
Fig 6. Creating alert rule
Once active, alerts appear in a centralised alerts dashboard, shown in Figure 7. This dashboard consolidates triggered alerts across projects, classifying them by type (e.g., API failures, credit exhaustion, low context relevance), along with the status (Healthy vs Triggered), and time last triggered. Developers can immediately see which parts of the pipeline require attention, mute or resolve alerts, and review historical patterns to detect recurring issues.
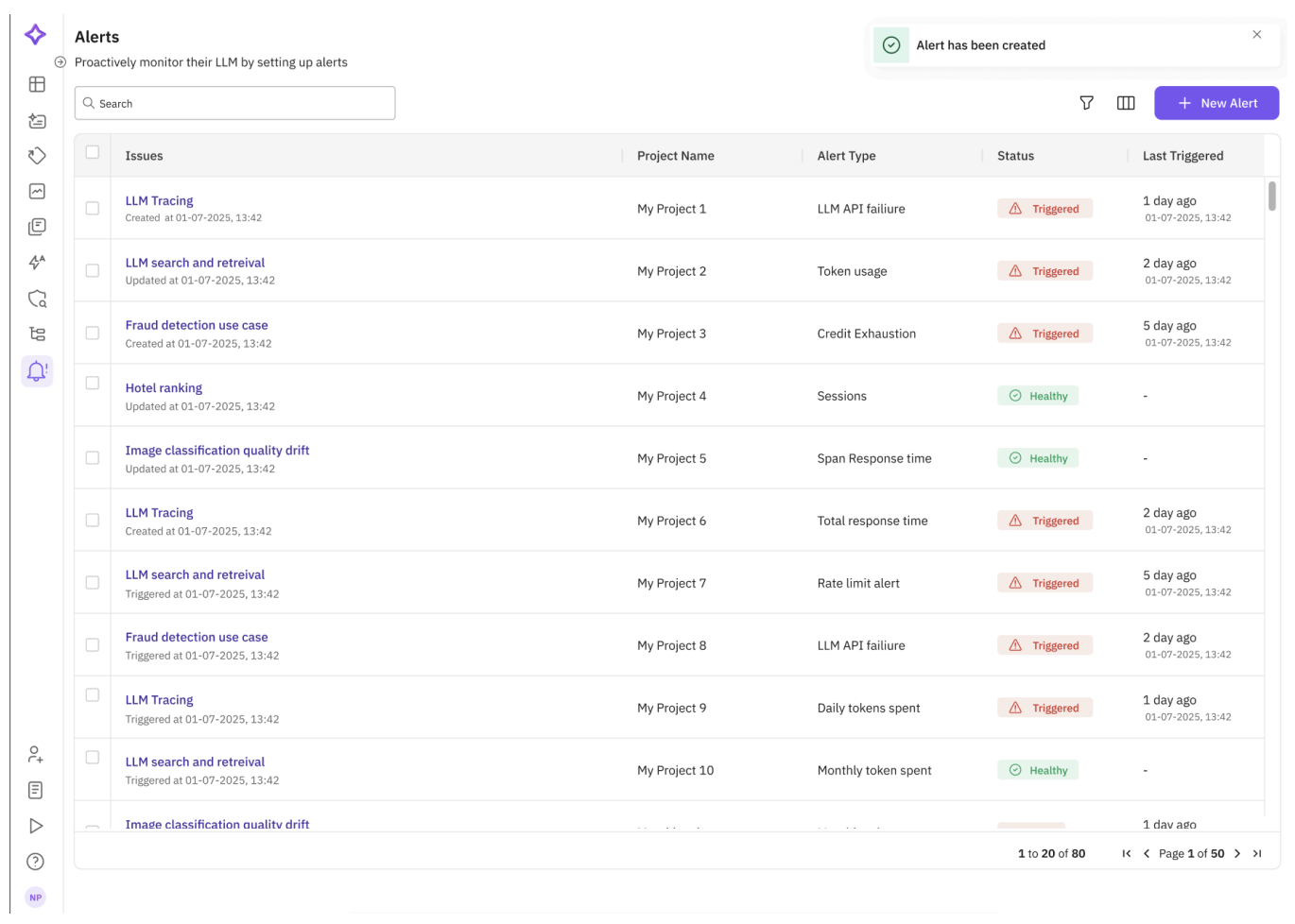 Fig 7. Alerts dashboard
By combining continuous evaluations with automated alerting, Future AGI transforms observability from a passive reporting system into an active safeguard. Teams no longer just understand how their RAG pipelines behave, they are warned the moment reliability drifts, enabling faster intervention, reduced risk, and stronger user trust.
Fig 7. Alerts dashboard
By combining continuous evaluations with automated alerting, Future AGI transforms observability from a passive reporting system into an active safeguard. Teams no longer just understand how their RAG pipelines behave, they are warned the moment reliability drifts, enabling faster intervention, reduced risk, and stronger user trust.
Conclusion
In this cookbook, we’ve shown how to combine MongoDB Atlas and Future AGI to build, evaluate, and monitor a document-grounded RAG system at production quality. MongoDB Atlas provides a robust foundation for storing and searching document embeddings, making it easy to implement scalable vector retrieval across enterprise PDFs. Future AGI adds the critical layer of observability and evaluation, enabling you to trace, test, and tune every stage of the LLM pipeline starting from document ingestion and chunk retrieval to prompt construction and final generation.
With structured tracing, real-time evals, and automated alerts, teams no longer need to rely on guesswork or wait for user complaints to diagnose issues. Instead, they gain immediate visibility into how the system behaves and whether it is performing to expectation. This unlocks faster iteration, reduced risk, and greater trust in the answers provided by your assistant.
Whether you’re debugging hallucinations, refining retrieval accuracy, or measuring adherence to prompt constraints, the combined tooling of MongoDB Atlas and Future AGI allows you to build RAG applications that are not only powerful, but explainable, resilient, and production-ready.
Ready to Build Trustworthy MongoDB Applications?
Start evaluating your MongoDB applications with confidence using Future AGI’s observability and evaluation framework. Future AGI provides the tools you need to build applications that are reliable, explainable, and production-ready.
Click here to schedule a demo with us now!