from dotenv import load_dotenv
load_dotenv()
import os
import json
import time
import requests
import pandas as pd
from fi.evals import Evaluator
# Define your evaluation data - CUSTOMIZE THIS SECTION
eval_data = [
{
"eval_template": "tone",
"model_name": "turing_large",
"inputs": {
"input": [
"This product is amazing!",
"I am very disappointed with the service."
]
}
},
{
"eval_template": "is_factually_consistent",
"model_name": "turing_large",
"inputs": {
"context": [
"What is the capital of France?",
"Who wrote Hamlet?"
],
"output": [
"The capital of France is Paris.",
"William Shakespeare wrote Hamlet."
]
}
}
]
def post_github_comment(content):
"""Posts a comment to a GitHub pull request."""
repo = os.getenv("REPO_NAME")
pr_number = os.getenv("PR_NUMBER")
token = os.getenv("GITHUB_TOKEN")
if not all([repo, pr_number, token]):
print("❌ Missing GitHub details. Skipping comment.")
return
url = f"https://api.github.com/repos/{repo}/issues/{pr_number}/comments"
headers = {
"Authorization": f"token {token}",
"Accept": "application/vnd.github.v3+json",
}
data = {"body": content}
response = requests.post(url, headers=headers, data=json.dumps(data))
if response.status_code == 201:
print("✅ Successfully posted comment to PR.")
else:
print(f"❌ Failed to post comment. Status code: {response.status_code}")
print(f"Response: {response.text}")
def format_failure_message(failure_reason):
"""Formats a failure message for GitHub comment."""
return f"""## ❌ Evaluation Failed
**Reason:** {failure_reason}
The evaluation could not be completed. Please check the logs and try again.
"""
def collect_all_metrics(evaluation_runs):
"""Collect all unique metrics from all evaluation runs."""
all_metrics = set()
for run in evaluation_runs:
results_summary = run.get('results_summary', {})
for key, value in results_summary.items():
if not isinstance(value, dict):
all_metrics.add(key)
else:
if isinstance(value, dict):
for sub_key in value.keys():
all_metrics.add(f"{key}_{sub_key}")
return sorted(list(all_metrics))
def get_metric_value(results_summary, metric):
"""Get the value of a metric from results summary."""
if metric in results_summary:
return results_summary[metric]
if '_' in metric:
parent_key, sub_key = metric.split('_', 1)
parent_data = results_summary.get(parent_key)
if isinstance(parent_data, dict) and sub_key in parent_data:
return parent_data[sub_key]
return 'N/A'
def format_value(value):
"""Format a value for display in the table."""
if isinstance(value, (int, float)):
if isinstance(value, float):
formatted = f"{value:.2f}".rstrip('0').rstrip('.')
return formatted if formatted else "0"
return str(value)
return str(value)
def create_comparison_table(evaluation_runs, current_version):
"""Create the comparison table data."""
version_data = {run.get('version'): run.get('results_summary', {}) for run in evaluation_runs}
all_metrics = collect_all_metrics(evaluation_runs)
comparison_data = []
for metric in all_metrics:
row = {'Metric': metric.replace('_', ' ').title()}
for version in sorted(version_data.keys()):
results = version_data[version]
value = get_metric_value(results, metric)
formatted_value = format_value(value)
version_label = f"{version} {'🔄' if version == current_version else ''}"
row[version_label] = formatted_value
comparison_data.append(row)
return comparison_data
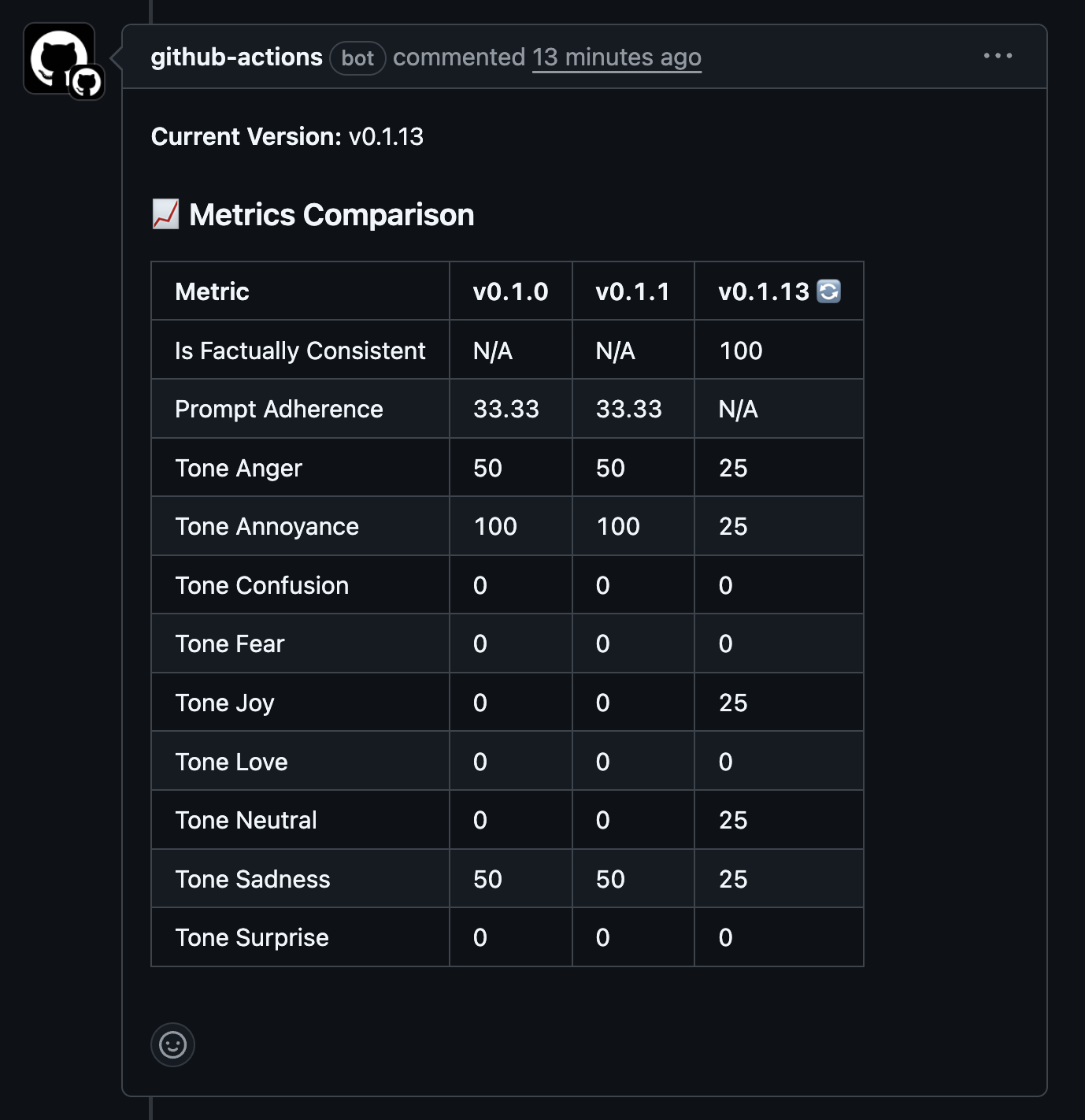
def format_version_comparison_results(evaluation_runs, current_version):
"""Formats multiple version results into a comparison table."""
if not evaluation_runs:
return "No evaluation results found."
comment = f"**Current Version:** {current_version}\n\n"
comparison_data = create_comparison_table(evaluation_runs, current_version)
if comparison_data:
df_comparison = pd.DataFrame(comparison_data)
comment += "### 📈 Metrics Comparison\n\n"
comment += df_comparison.to_markdown(index=False)
comment += "\n\n"
return comment
def poll_for_completion(evaluator, project_name, current_version, comparison_versions_str="", max_wait_time=600, poll_interval=30):
"""Polls for evaluation completion by fetching all versions."""
start_time = time.time()
comparison_versions = []
if comparison_versions_str:
comparison_versions = [v.strip() for v in comparison_versions_str.split(',') if v.strip()]
all_versions = list(set([current_version] + comparison_versions))
print(f"ℹ️ Will poll for completion of versions: {all_versions}")
while time.time() - start_time < max_wait_time:
try:
elapsed_time = int(time.time() - start_time)
print(f"⏳ Polling for results (elapsed: {elapsed_time}s/{max_wait_time}s)...")
# Use the core SDK function to get results
result = evaluator.get_pipeline_results(
project_name=project_name,
versions=all_versions
)
if result.get('status'):
api_result = result.get('result', {})
status = api_result.get('status', 'unknown')
evaluation_runs = api_result.get('evaluation_runs', [])
print(f"⏳ API status: {status}. Found {len(evaluation_runs)} runs.")
if status == 'completed':
print(f"✅ All requested versions are complete.")
return evaluation_runs
elif status in ['failed', 'error', 'cancelled']:
print(f"❌ Evaluation failed with status: {status}")
return None
else:
print("❌ Failed to get a valid response from evaluation API")
except Exception as e:
print(f"❌ Error polling for results: {e}")
time.sleep(poll_interval)
print(f"⏰ Timeout waiting for evaluation completion after {max_wait_time} seconds")
return None
def main():
"""Main function to run evaluation, poll for completion, and post results to GitHub."""
print("🚀 Starting evaluate_pipeline.py main function")
# Get environment variables
project_name = os.getenv("PROJECT_NAME", "Voice Agent")
version = os.getenv("VERSION", "v0.1.0")
comparison_versions = os.getenv("COMPARISON_VERSIONS", "")
# Initialize the Future AGI evaluator (Core SDK Function)
try:
evaluator = Evaluator(
fi_api_key=os.getenv("FI_API_KEY"),
fi_secret_key=os.getenv("FI_SECRET_KEY")
)
print("✅ Evaluator initialized successfully")
except Exception as e:
failure_message = format_failure_message(f"Failed to initialize evaluator: {e}")
post_github_comment(failure_message)
return
print(f"🚀 Starting evaluation for project: {project_name}, version: {version}")
# Submit evaluation pipeline (Core SDK Function)
try:
result = evaluator.evaluate_pipeline(
project_name=project_name,
version=version,
eval_data=eval_data
)
if not result.get('status'):
failure_reason = f"Failed to submit evaluation: {result}"
post_github_comment(format_failure_message(failure_reason))
return
print(f"✅ Evaluation submitted successfully. Run ID: {result.get('result', {}).get('evaluation_run_id')}")
except Exception as e:
failure_reason = f"Error submitting evaluation: {e}"
post_github_comment(format_failure_message(failure_reason))
return
# Poll for completion and get results (Core SDK Function)
all_runs = poll_for_completion(evaluator, project_name, version, comparison_versions)
if not all_runs:
failure_reason = "Evaluation timed out or failed during processing"
post_github_comment(format_failure_message(failure_reason))
return
# Format and post results to GitHub PR
print(f"📊 Retrieved results for {len(all_runs)} versions")
comment_body = format_version_comparison_results(all_runs, version)
post_github_comment(comment_body)
print("🎉 Script completed successfully!")
if __name__ == "__main__":
main()