Streaming
Use Server-Sent Events (SSE) streaming with Prism for real-time LLM responses.
About
Prism supports full Server-Sent Events (SSE) streaming, a standard protocol where the server pushes data to the client incrementally as it becomes available, rather than waiting for a complete response. This is identical to the OpenAI streaming format. Set "stream": true and receive response chunks in real-time. Works across all providers. Prism translates each provider’s native streaming format to standard OpenAI SSE format.
When to use
- Real-time chat interfaces: Display tokens as they arrive for responsive user experience
- Long-form generation: Stream articles, reports, or code without waiting for the full response
- Voice and TTS pipelines: Feed tokens to downstream processors incrementally
How to
Enable streaming in your request
Set "stream": true in your request payload to the Prism gateway.
Handle SSE events
Connect to the streaming endpoint and process incoming SSE events as they arrive.
Parse completion chunks
Each event contains a delta with the next token. Accumulate deltas to reconstruct the full response.
Basic Streaming
The following diagrams illustrate the difference between blocking (non-streaming) and streaming responses:
Blocking (non-streaming) request:
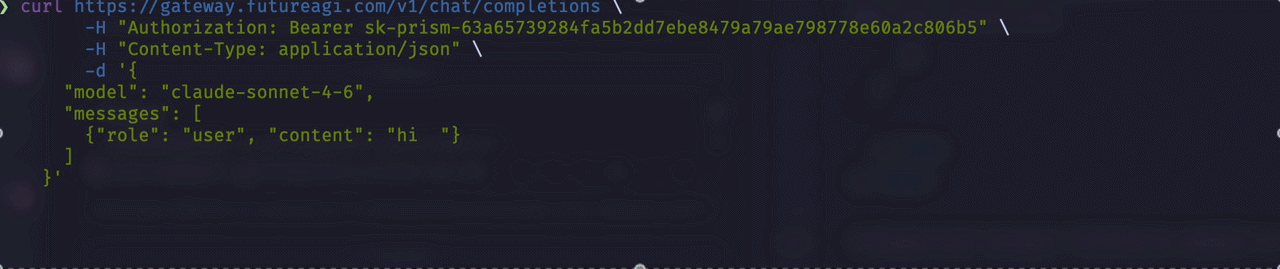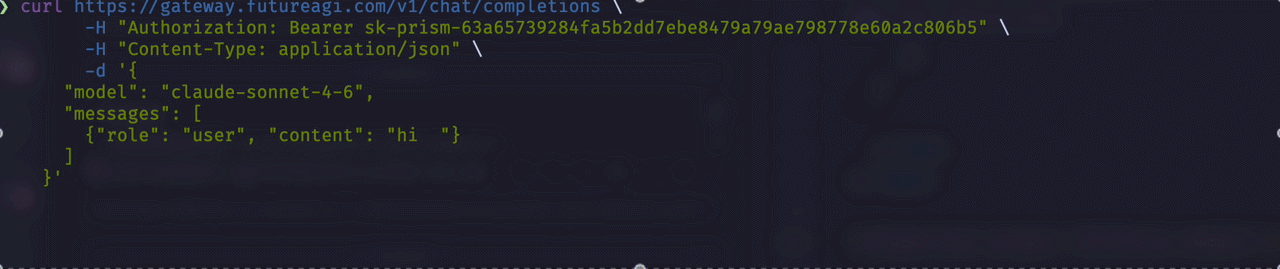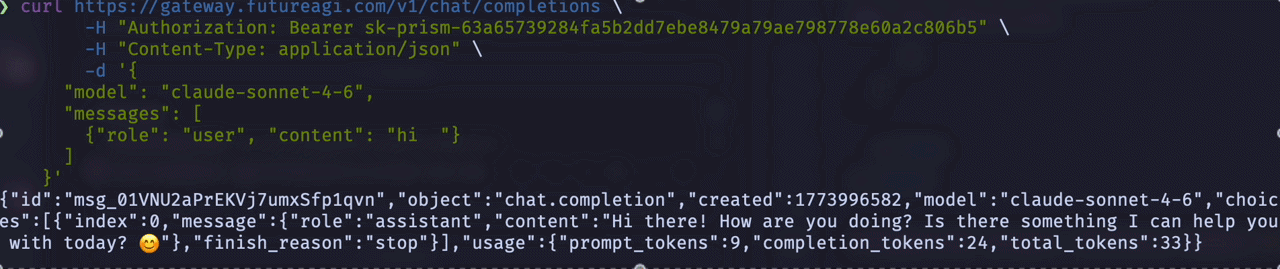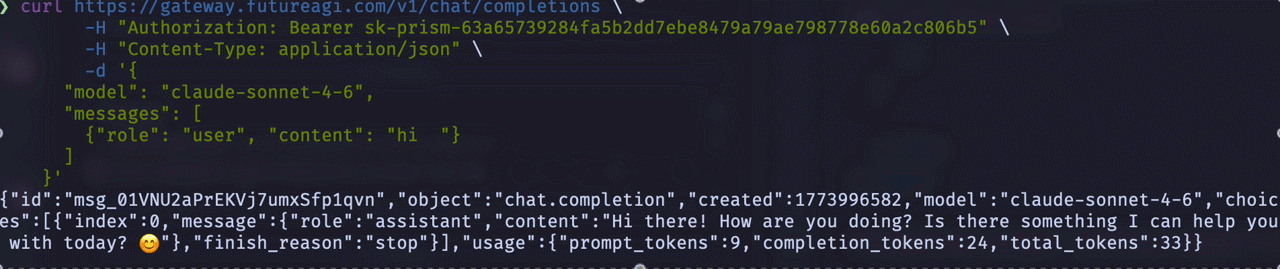
In a blocking request, the client sends a request and waits for the entire response to be generated before receiving any data.
Streaming request:
In a streaming request, the client receives tokens as they are generated, enabling real-time display of the response.
curl https://gateway.futureagi.com/v1/chat/completions \
-H "Authorization: Bearer sk-prism-your-key" \
-H "Content-Type: application/json" \
-d '{
"model": "gpt-4o-mini",
"messages": [
{"role": "user", "content": "Write a short poem"}
],
"stream": true
}'from prism import Prism
client = Prism(
api_key="sk-prism-your-key",
base_url="https://gateway.futureagi.com"
)
stream = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{"role": "user", "content": "Write a short poem"}
],
stream=True
)
for chunk in stream:
if chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end="", flush=True)import { Prism } from '@futureagi/prism';
const client = new Prism({
apiKey: 'sk-prism-your-key',
baseUrl: 'https://gateway.futureagi.com'
});
const stream = await client.chat.completions.create({
model: 'gpt-4o-mini',
messages: [
{ role: 'user', content: 'Write a short poem' }
],
stream: true
});
for await (const chunk of stream) {
if (chunk.choices[0].delta.content) {
process.stdout.write(chunk.choices[0].delta.content);
}
}Stream Manager
The Stream Manager provides a managed context for streaming with automatic resource cleanup and access to the full completion after streaming completes.
from prism import Prism
client = Prism(
api_key="sk-prism-your-key",
base_url="https://gateway.futureagi.com"
)
with client.chat.completions.stream(
model="gpt-4o-mini",
messages=[
{"role": "user", "content": "Explain quantum computing"}
]
) as stream:
for text in stream.text_stream:
print(text, end="", flush=True)
# Access full completion after streaming
completion = stream.get_final_completion()
print(f"\nTotal tokens: {completion.usage.total_tokens}")import { Prism } from '@futureagi/prism';
const client = new Prism({
apiKey: 'sk-prism-your-key',
baseUrl: 'https://gateway.futureagi.com'
});
const stream = await client.chat.completions.stream({
model: 'gpt-4o-mini',
messages: [
{ role: 'user', content: 'Explain quantum computing' }
]
});
for await (const chunk of stream) {
if (chunk.choices[0].delta.content) {
process.stdout.write(chunk.choices[0].delta.content);
}
}
const completion = stream.finalCompletion();
console.log(`Total tokens: ${completion.usage.total_tokens}`);SSE Format
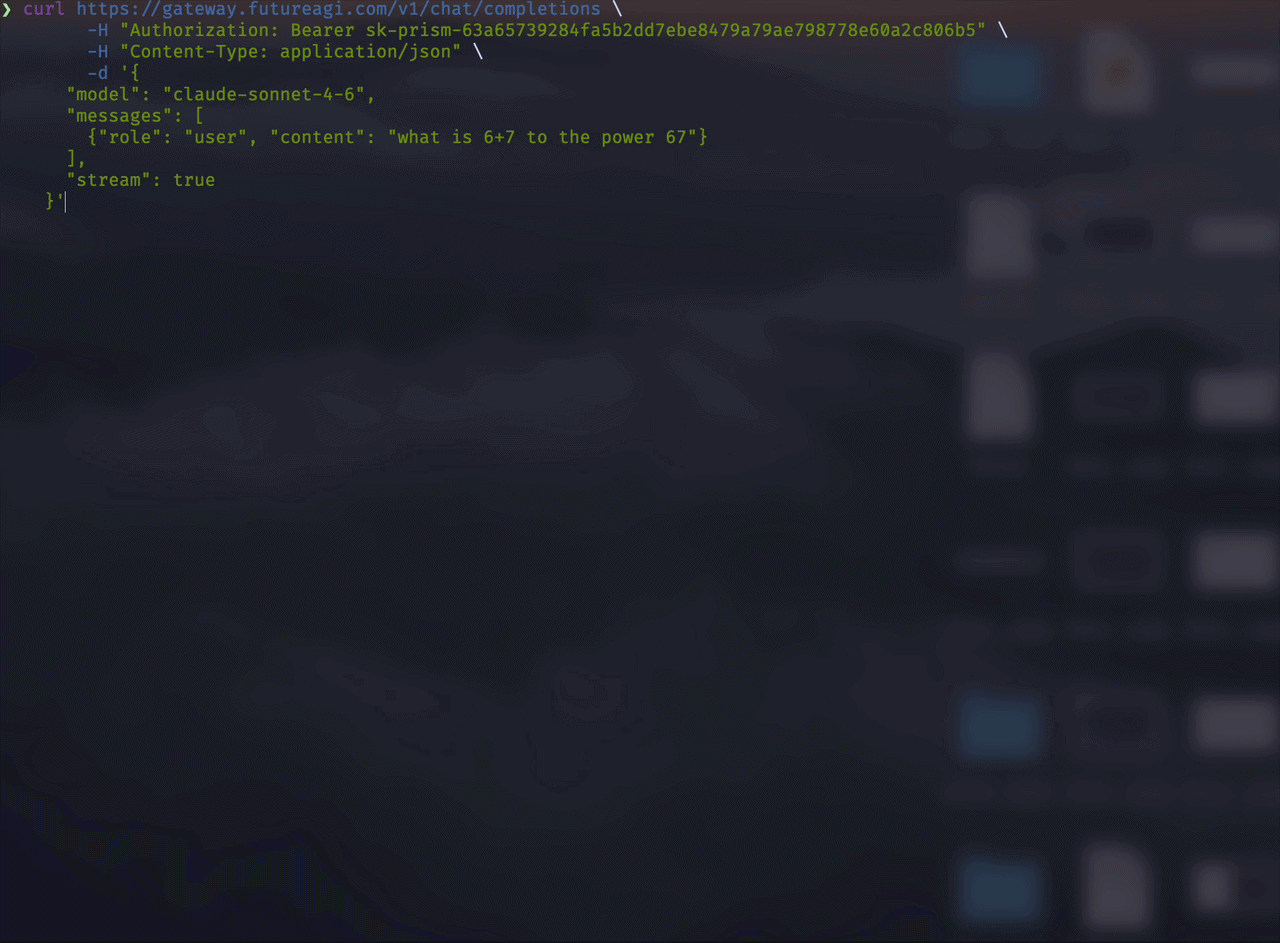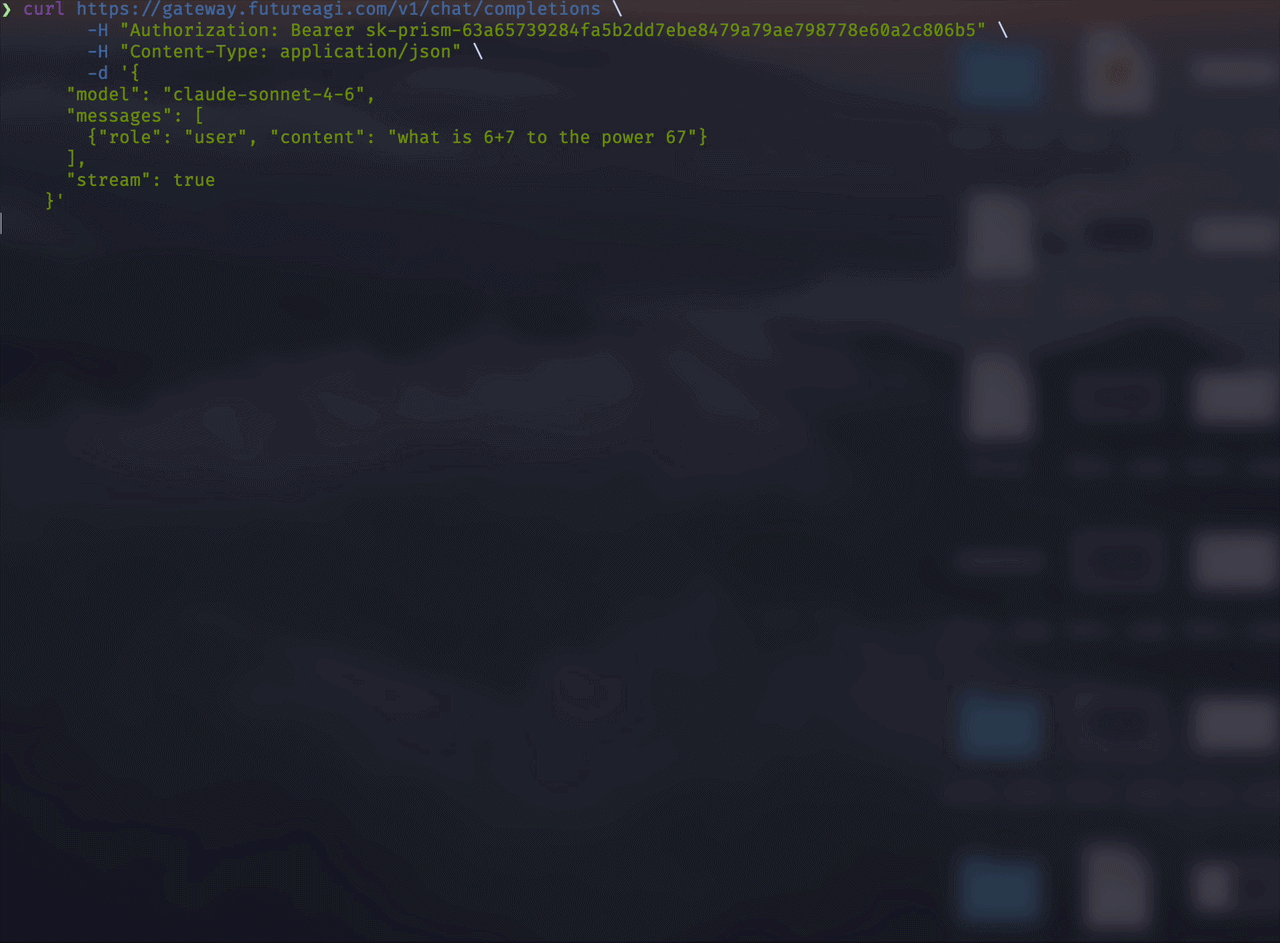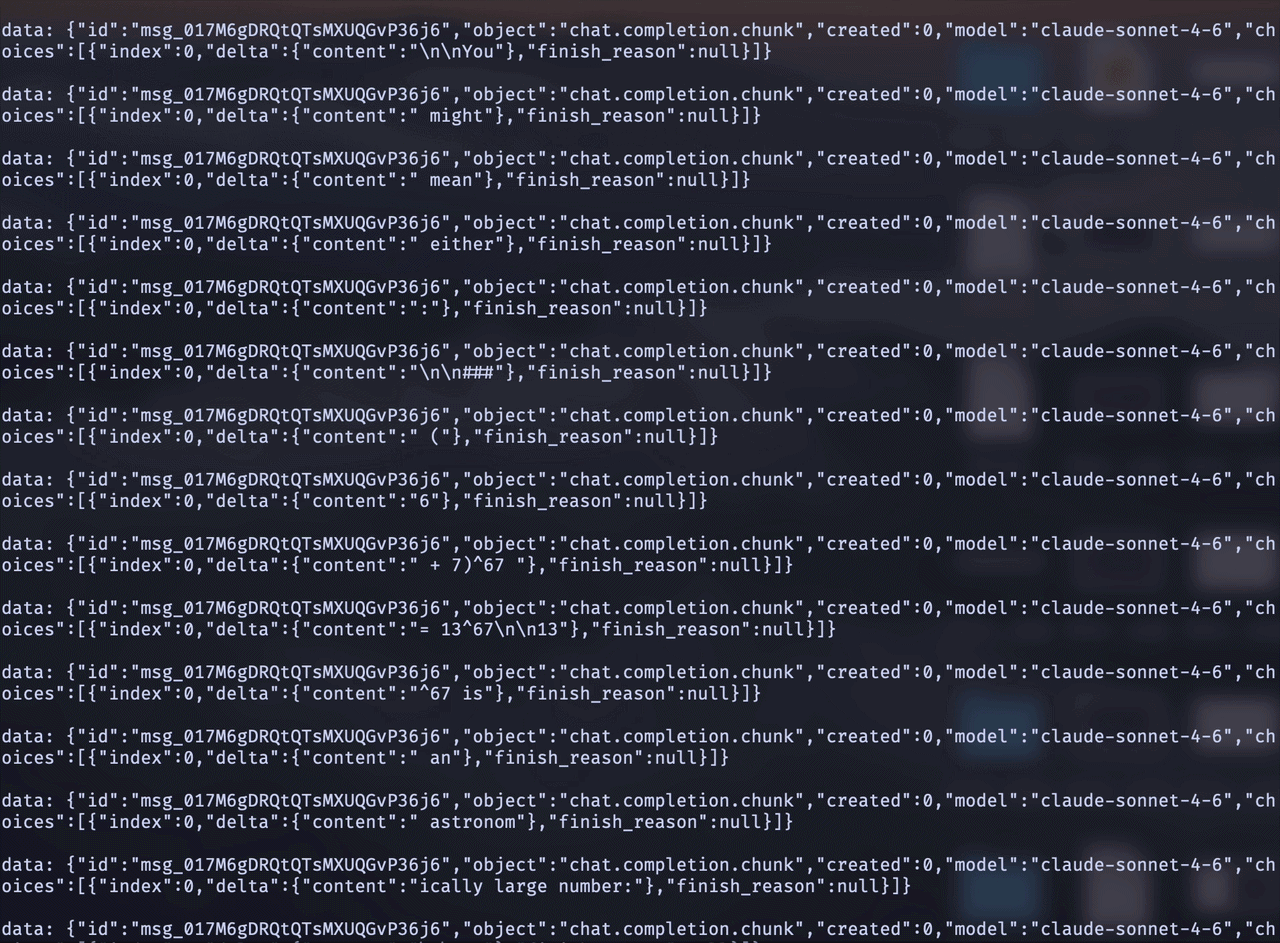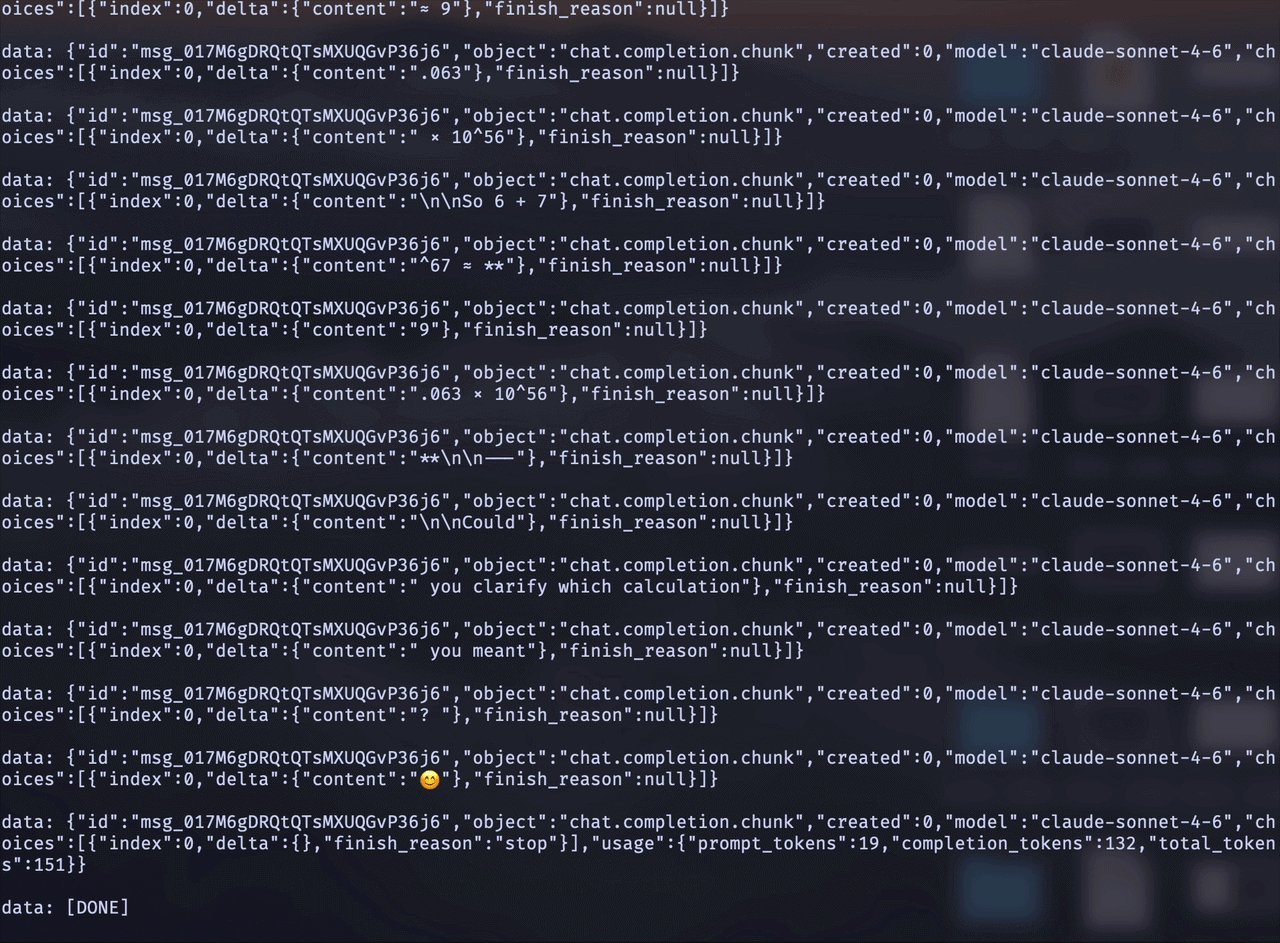
Streaming responses follow the standard OpenAI SSE format:
data: {"id":"chatcmpl-123","object":"chat.completion.chunk","created":1234567890,"model":"gpt-4o-mini","choices":[{"index":0,"delta":{"role":"assistant","content":"Hello"},"finish_reason":null}]}
data: {"id":"chatcmpl-123","object":"chat.completion.chunk","created":1234567890,"model":"gpt-4o-mini","choices":[{"index":0,"delta":{"content":" world"},"finish_reason":null}]}
data: [DONE]Each event contains a delta with the next token or function call. The stream ends with a [DONE] message.
Streaming with Guardrails
Post-processing guardrails accumulate chunks as they stream. If a guardrail triggers in Enforce mode, the stream terminates immediately with an error. In Monitor mode, a warning is logged but streaming continues.
Note
Streaming with Caching
Streaming requests bypass the cache entirely. Each streaming request goes directly to the provider, ensuring real-time responses.
Cross-Provider Streaming
Prism translates streaming from all providers to the standard OpenAI SSE format:
- Anthropic: Converts Claude’s streaming format to OpenAI chunks
- Gemini: Translates Google’s streaming protocol to SSE
- Bedrock: Adapts AWS Bedrock streaming to OpenAI format
Your application receives identical SSE events regardless of the underlying provider.