What is Future AGI?
Future AGI is the end-to-end platform for building, evaluating, observing, and making AI agents reliable
Future AGI is an end-to-end platform for building reliable AI agents. It brings simulation, evaluation, guardrails, tracing, optimization, and an LLM gateway into one place, so the work of shipping a trustworthy agent, and keeping it trustworthy, happens in a single connected loop instead of across disconnected tools
It’s built for the whole team shipping AI (engineers, product managers, and domain experts working from one source of truth), and it works with the stack you already use. If you use it, we probably support it. You can start with a single line of code
The Learning Loop
Every part of Future AGI feeds the next. You prototype and simulate an agent before launch, evaluate its outputs against built-in and custom metrics, observe real traffic once it’s live, and optimize from what you learn, then the cycle repeats
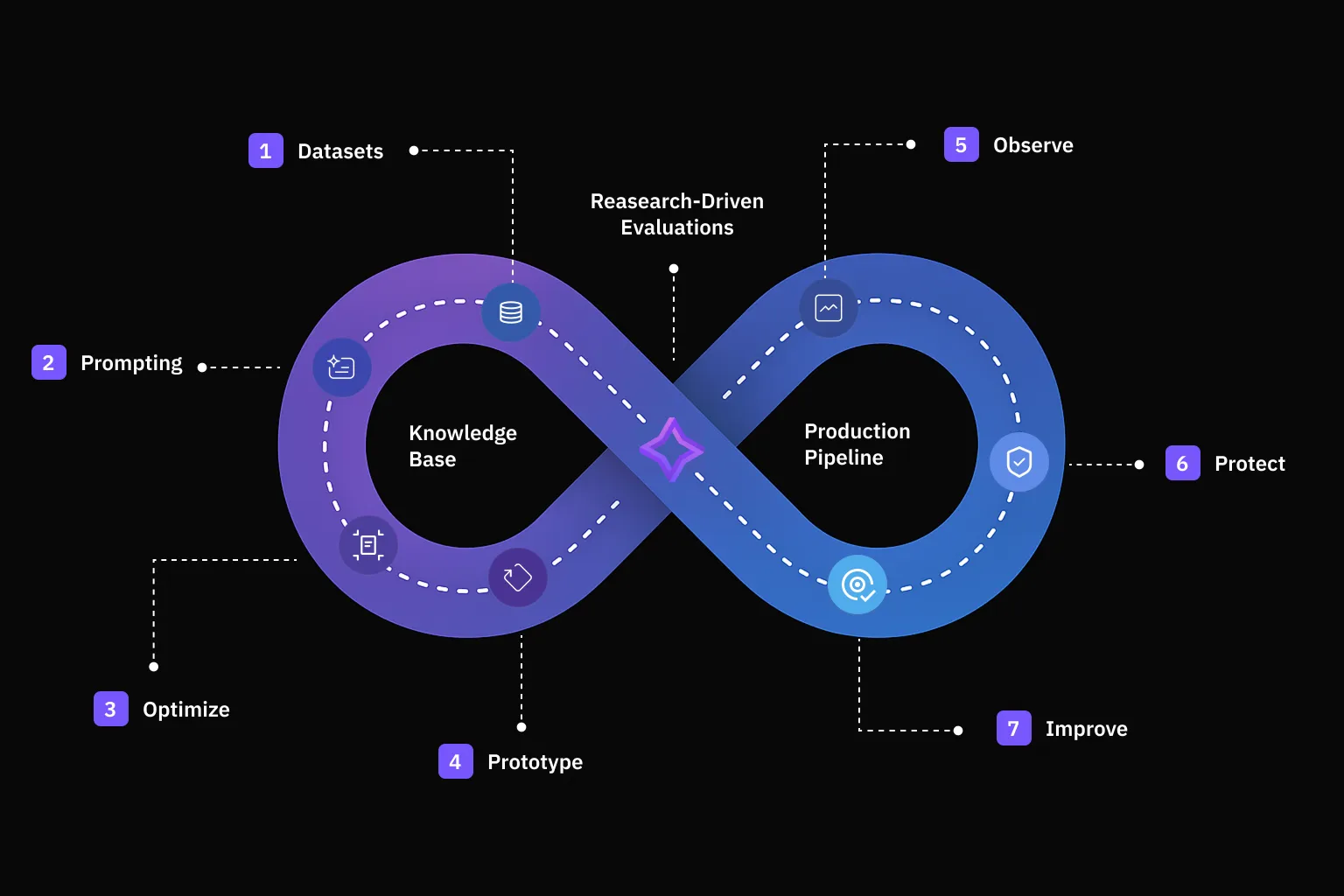
Because every product shares the same traces, datasets, and scores, the work compounds: a trace you capture becomes evaluation data, an evaluation result becomes an optimization signal, and a dataset feeds simulations and experiments alike. That shared spine is the mental model for everything below
Explore the platform
Future AGI is organized into six broad areas:
Prototype your agent
Agent Command Center
Simulate
Evaluate
Observe
Optimize
Explore Falcon
Bring your data in
The fastest way to see Future AGI is to get your data flowing:
- Send your first trace
- Route your first LLM request
- Add your first agent definition
- Create your first prompt
Note
Using Cursor or Claude Code? Install the Future AGI MCP server to bring the platform and docs straight into your editor. See Set up the MCP server
Questions & Discussion