Prompt Simulation: Test Prompts in Multi-Turn Conversations
Test your prompts in realistic multi-turn conversations directly from the Prompt Workbench, with no agent deployment or SDK required.
About
Prompt Simulation lets you run your prompt template against realistic customer scenarios in multi-turn chat conversations — all from within the Prompt Workbench. Instead of waiting until after deployment to discover how your prompt performs in real conversations, you can test, evaluate, and iterate right away.
When you run a simulation, the platform uses your prompt version as the “agent” and pairs it against a simulated customer driven by a scenario you define. Each scenario row becomes one chat conversation (up to 10 turns). When the conversations finish, any attached evaluations run automatically and produce scores and summaries you can act on immediately.
Note
Prompt simulation is distinct from agent-based simulation. You don’t need an agent definition, an external deployment (e.g. Vapi, Retell), or any SDK code. Everything runs inside the Prompt Workbench.
When to use
- Test before you ship — Run your prompt against realistic customer scenarios (refunds, support, onboarding) and review transcripts and eval scores before deploying to production.
- Compare prompt versions — Create simulations for different saved versions of the same template and run them on the same scenarios to see which version performs better.
- Validate multi-turn behaviour — See how your prompt handles follow-up questions, objections, or edge cases over several turns instead of judging it from single prompts in the Playground.
- Catch regressions — After changing your prompt, re-run the same simulation and compare results so you spot unintended changes in tone, task completion, or safety.
- Tune evals — Attach evaluations (task completion, tone, custom metrics) and use simulation runs to calibrate or improve your eval setup before using it on production traffic.
- No agent or SDK — Get conversation-level feedback without building an agent definition or writing integration code; everything stays in the Prompt Workbench.
Key Concepts
| Concept | What it is |
|---|---|
| Prompt Template | The container for your prompt (name, description, variable names). Lives in the Prompt Workbench. |
| Prompt Version | A saved snapshot of the template (system message, model, parameters). The simulation uses one version as the “agent.” |
| Scenario | Defines who the simulated customer is and what they do. Types: dataset, script, or graph. Each row in a scenario → one chat session. |
| Persona | Demographics and personality traits attached to a scenario. Controls how the simulated customer behaves (e.g. “frustrated buyer,” “detail-oriented user”). |
| Simulation (Run Test) | The saved config: which prompt version + which scenarios + which evals. Created from the Simulation tab. |
| Test Execution | One run of a simulation. Created when you click Run Simulation. Tracks overall status and aggregated results. |
| Call Execution | One chat session (one scenario row). Stores the transcript, eval outputs, token counts, and latency. |
| Eval Config | An evaluation attached to the simulation. Runs automatically after each chat completes. |
How to
Before you start: have a prompt template with at least one saved prompt version and at least one scenario (see Scenarios).
Open the Simulation tab
- Go to Prompts in the sidebar.
- Open your prompt template.
- Click the Simulation tab at the top of the workbench (next to Playground, Evaluation, and Metrics).
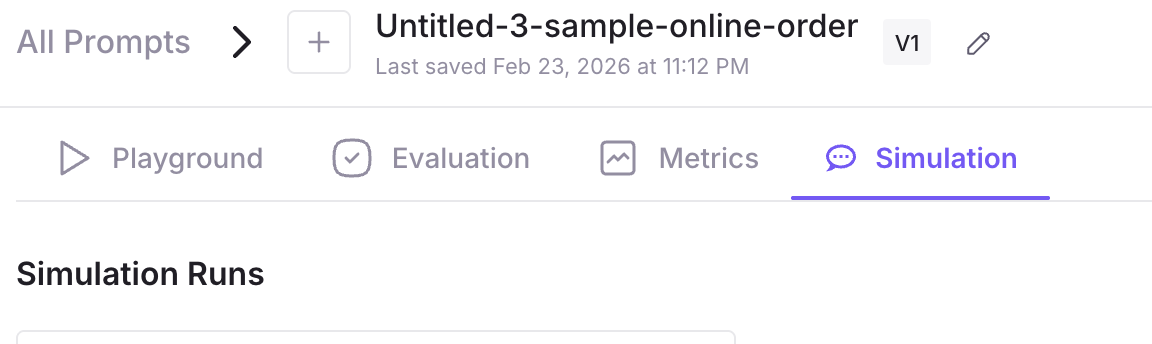 You’ll see a list of existing simulations for this template, a View Docs button, and a + Create a Simulation button. Click + Create a Simulation to begin.
You’ll see a list of existing simulations for this template, a View Docs button, and a + Create a Simulation button. Click + Create a Simulation to begin.
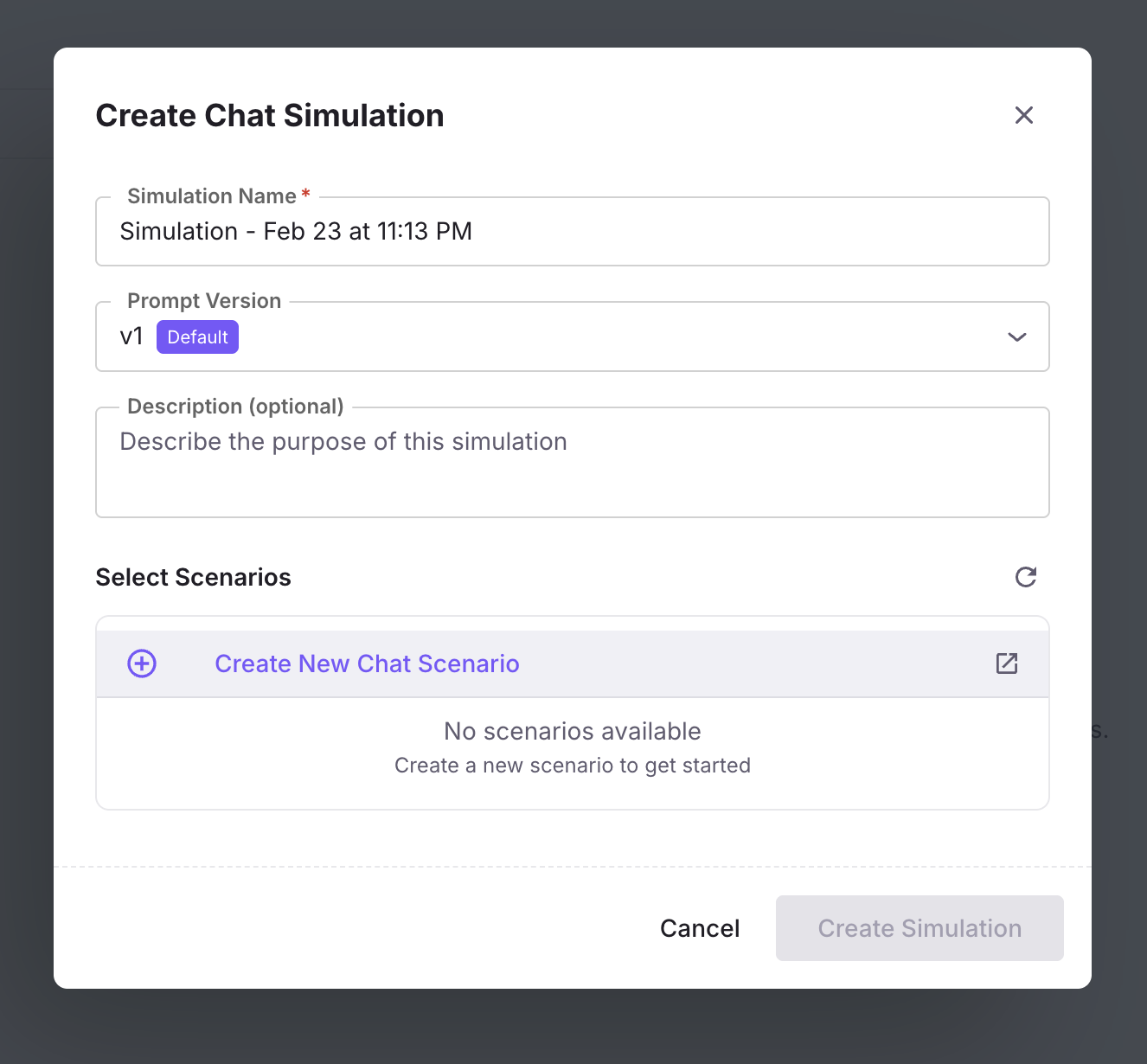
Create a simulation
Click + Create a Simulation. The form walks you through four steps — complete each one and click Next; use Back to change earlier steps. Next stays disabled until required fields on the current step are filled.
Add simulation details
- Simulation name (required) — Enter a name for your simulation run (e.g. “Sales agent performance test” or “Refund flow - v3”). This identifies the simulation in the list.
- Choose Prompt version (required) — Select the saved version of this prompt template that will act as the “agent” in every chat. The dropdown shows versions available for the current template.
- Description (optional) — Describe what this simulation will evaluate (e.g. “Testing refund handling after prompt update”).
- Click Next to go to scenario selection.
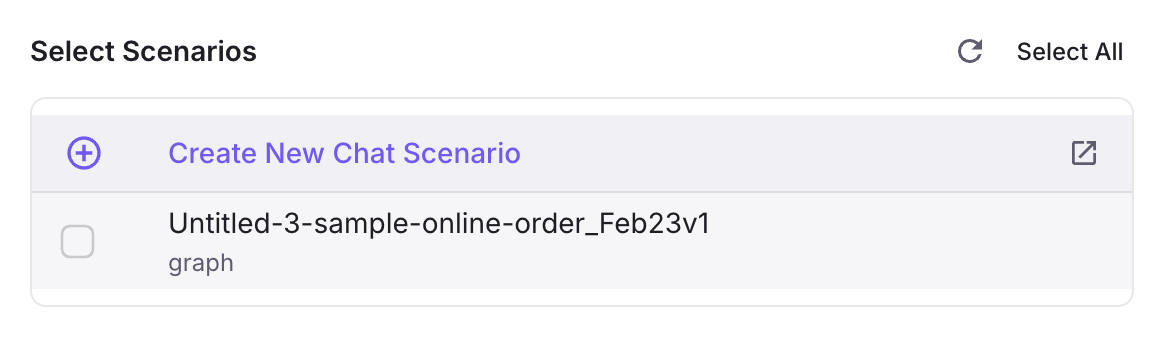
Choose Scenario(s)
- The screen says: Choose your scenarios — scenarios that your prompt will be tested against.
- Use the Search scenarios… bar to find scenarios by name if you have many.
- A list of scenarios is shown. Each row has: a checkbox to select, Name and description, a type tag (e.g. Dataset, Graph), and a row count (each row becomes one chat session when you run).
- Select at least one scenario. You can select multiple; the total number of chats in a run is the sum of rows across selected scenarios.
- Click Next. Next stays disabled until at least one scenario is selected.
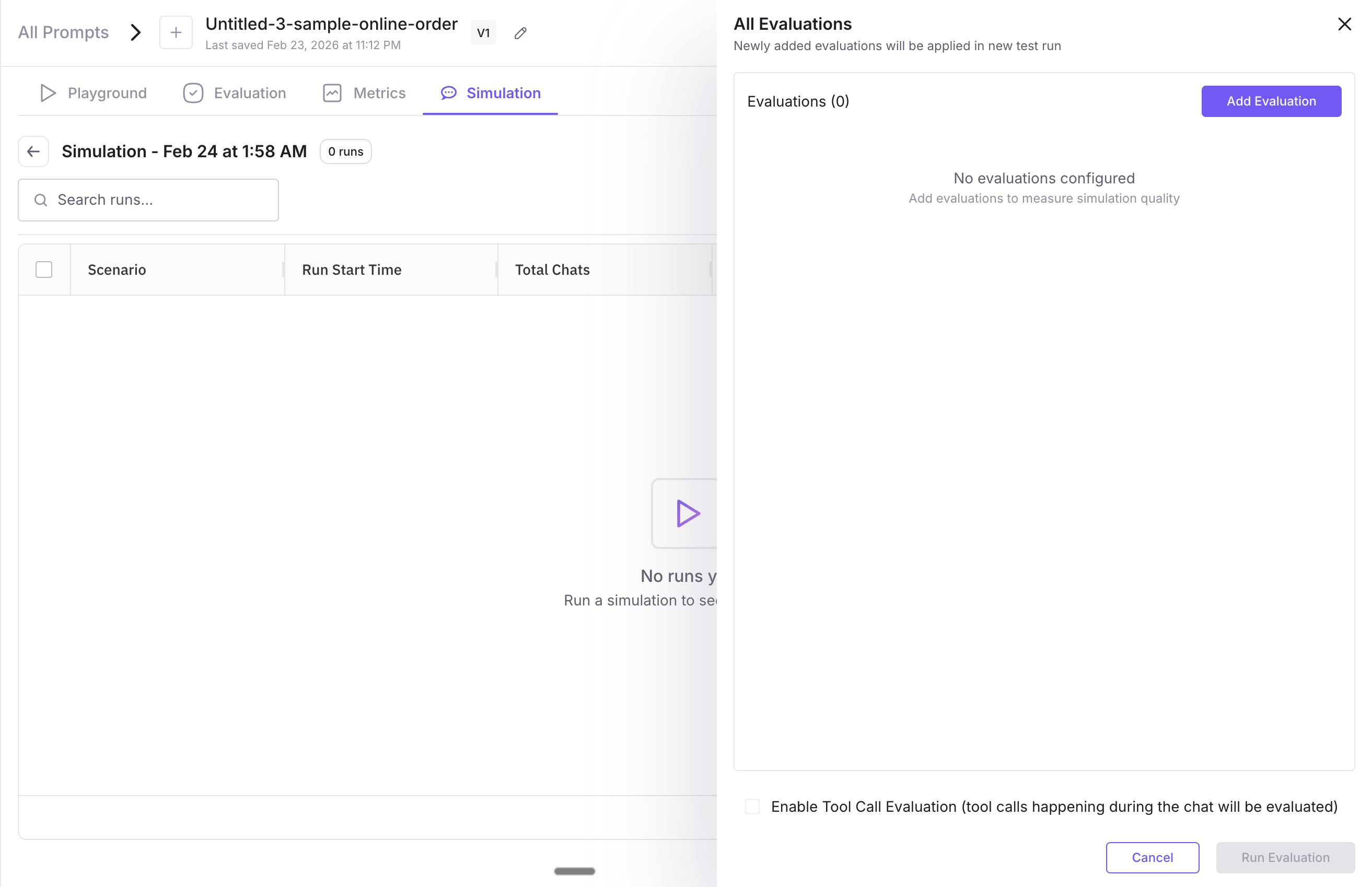
Select Evaluations
- The screen says: Select evaluations — apply evaluation metrics to measure your prompt’s performance.
- Enable tool call evaluation — A toggle. When on, tool/function calls during chats will be evaluated. Turn it on only if your prompt uses tools.
- + Add Evaluations — Click to open the Evaluations picker. You can choose from pre-built evals (filter by Use Cases, Eval Categories, Eval Type; search by name) or create your own evals. Added evals appear in the list. Evals are optional. Click Next when done.
Summary
- Review your simulation configuration before creating it. Three sections: Test Configuration (name, prompt version), Selected Test Scenarios (count and details), Selected Evaluations (count). Click Back to fix anything; when satisfied, complete the flow to create the simulation. You’re then taken to the simulation detail view.
- If you’re asked to Update Keys for test (e.g. API Key, Assistant ID), fill in the required fields and save.
Configure the simulation (optional)
From the simulation detail view you can adjust settings before running:
- Version — Switch which prompt version is used. Useful for A/B comparisons between versions on the same scenario set.
- Scenarios — Add or remove scenarios. At least one is required to run.
- Evals — Add, edit, or remove evaluation configs. Evals run automatically after each chat completes.
Run the simulation
- On the simulation detail view, click Run Simulation in the top-right corner.
- A confirmation notification appears and the run begins.
The platform will: create one test execution for this run; resolve all attached scenarios into rows; create one call execution (chat session) per row; run each chat (your prompt version as the agent, the scenario’s simulator as the customer, up to 10 turns per conversation); run all attached eval configs after each chat completes.
Tip
You can run the same simulation multiple times (e.g. after changing your prompt version or scenarios). Each click of Run Simulation creates a new test execution, so all historical runs are preserved.
View results
Click any execution row on the simulation detail view to open Execution Detail. Here you see a run-level summary at the top and a list of every chat below; use the tabs to understand what each area shows and how to use it.
The top panel gives you a quick read on the whole run. Use it to see overall health (how many chats completed), cost (tokens), and how your prompt scored on the evals you attached.
| Metric group | What you see |
|---|---|
| Chat Details | Total chats, how many completed, and completion percentage — tells you whether the run finished cleanly or had failures. |
| System Metrics | Average total, input, and output tokens per chat, and average latency (ms). Use this to spot high-cost or slow conversations. |
| Evaluation Metrics | Average score for each evaluation you configured (e.g. Task Completion, Tone). Click View all metrics for a full breakdown across evals and chats. |
Use these numbers to compare runs (e.g. before vs after a prompt change) or to spot runs that need a closer look in the grid.
The grid lists every chat (one per scenario row). Each row is one conversation: status, scores, and usage. Use it to find failed or low-scoring chats, compare behaviour across scenarios, or pick chats to drill into.
| Column | What it tells you |
|---|---|
| Chat Details | Status (Completed / Failed), start time, and number of turns. Use status to quickly find failures. |
| CSAT | Customer satisfaction score for that chat, with a color indicator. |
| Total / Input / Output Tokens | Token usage for that conversation — useful for cost and length. |
| Average Latency (ms) | How long the model took to respond on average in that chat. |
| Turn Count | Number of back-and-forth exchanges (up to 10 per run). |
| Evaluation Metrics | Per-eval results as tags (e.g. Tone: Joy, Neutral, Annoyance). Scan to see which chats passed or failed which evals. |
Use the Search bar and Filter icon to narrow by status, score, or other criteria.
Drill into one conversation: click any chat row in the grid to open that chat’s detail view. You get the full transcript (every message from your prompt and the simulated customer), plus that chat’s eval scores and token/latency breakdown. Use this to see why a chat failed an eval, how the model responded to tricky turns, or to copy a conversation for debugging or training.
Take action on results
| Action | How |
|---|---|
| Re-run simulation | Click Re-run from the execution detail to run the same simulation again. |
| Rerun selected calls | Rerun only certain chats from an execution. |
| Rerun whole execution | Rerun all chats in that execution. |
| Cancel a run | Stop a run in progress. |
| Export data | Download results as CSV. |
| Fix My Agent | AI-powered suggestions to improve your prompt. |
| Add More Evals | Attach more evaluations and run on completed conversations. |
Next Steps
Scenarios
Learn how to create scenarios with datasets and personas.
Fix My Agent
Use AI-powered suggestions to improve your prompt based on simulation results.
Create Custom Evals
Build evaluations tailored to your specific use case.
Simulation Using SDK
Run simulations against a deployed voice or chat agent programmatically.
Questions & Discussion