Cut LLM Costs 80% With Semantic Caching in Agent Command Center
Turn on exact and semantic response caching at the gateway so paraphrased duplicate prompts return cached answers instead of paying for the same call twice.
Enable caching once in the Agent Command Center dashboard, switch the strategy to semantic, and your existing OpenAI SDK code starts returning cached answers for paraphrased prompts. The x-agentcc-cache: hit_semantic response header confirms it. You walk away with sub-100ms latency and near-zero cost on duplicate traffic, no application-code rewrites.
| Time | Difficulty | Package |
|---|---|---|
| 10 min | Beginner | agentcc |
- FutureAGI account → app.futureagi.com
- Agent Command Center API key starting with
sk-agentcc-(Settings → API Keys) - At least one LLM provider configured in Agent Command Center → Providers
- Python 3.9+
Install
Install the OpenAI and Agent Command Center SDKs and set your API key.
pip install openai agentccexport AGENTCC_API_KEY="sk-agentcc-your-key"Tutorial
Send a baseline request and note the cost
Point the OpenAI SDK at the gateway and send a request. The response headers tell you exactly what it cost and whether it came from cache.
import os
from openai import OpenAI
API_KEY = os.environ["AGENTCC_API_KEY"]
client = OpenAI(
api_key=API_KEY,
base_url="https://gateway.futureagi.com/v1",
)
r = client.chat.completions.with_raw_response.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": "What is your return policy?"}],
)
print(f"cache: {r.headers.get('x-agentcc-cache')}")
print(f"cost: ${r.headers.get('x-agentcc-cost')}")
print(f"latency: {r.headers.get('x-agentcc-latency-ms')}ms")x-agentcc-cache is empty or miss on a fresh call. The cost and latency are what you’d pay every time without caching.
Turn on exact caching in the dashboard
In the dashboard, go to Gateway → Providers → Cache and click Configure Cache. Toggle:
- Enable Response Cache: on
- Default TTL:
1h(or whatever fits your data freshness needs)
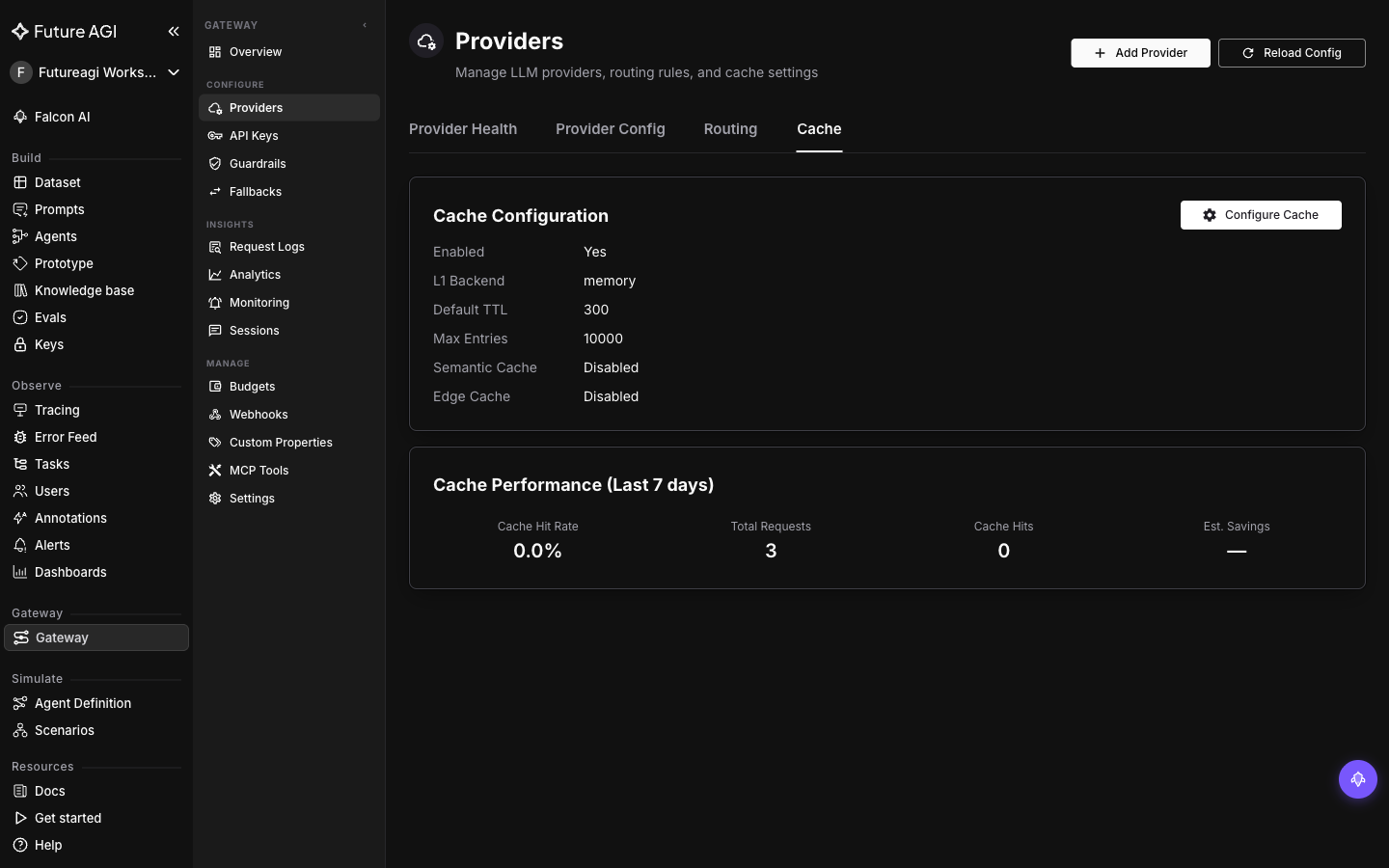
Save. Caching is now active for every request through the gateway. The Cache Configuration card shows Enabled: Yes with L1 Backend: memory (the L1 layer is always exact-match; memory just means it’s stored in-process. You can switch to Redis or disk for a multi-instance gateway). Semantic Cache: Disabled confirms only exact matches are served right now. No client change required. Run the same prompt twice:
prompt = [{"role": "user", "content": "What is your return policy?"}]
r1 = client.chat.completions.with_raw_response.create(model="gpt-4o-mini", messages=prompt)
print(f"call 1: {r1.headers.get('x-agentcc-cache')} | ${r1.headers.get('x-agentcc-cost')}")
r2 = client.chat.completions.with_raw_response.create(model="gpt-4o-mini", messages=prompt)
print(f"call 2: {r2.headers.get('x-agentcc-cache')} | ${r2.headers.get('x-agentcc-cost')}")Call 1 is miss. Call 2 is hit_exact, instant, with $0 provider cost. Exact caching is fast and free, but only helps when prompts are byte-identical.
Tip
Use cache namespaces to isolate environments or experiments. Set x-agentcc-cache-namespace: staging on a request to keep its cache separate from production. Each namespace is independent. A prod hit won’t leak into staging.
Switch to semantic caching for paraphrased prompts
Real users don’t ask the same question the same way twice. Semantic caching matches prompts by meaning rather than exact text. It runs as an L2 fallback after the L1 exact-match check.
In the same Configure Cache dialog, enable:
- L2 Semantic Cache: on
- Threshold:
0.92(similarity, 0 to 1, higher is stricter)
The same client code now matches paraphrases:
prompts = [
"What is your return policy?",
"Can I return a product I bought?",
"How do refunds work at your store?",
"Tell me about returning items.",
]
for p in prompts:
r = client.chat.completions.with_raw_response.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": p}],
)
print(f"{(r.headers.get('x-agentcc-cache') or 'miss'):14} | ${r.headers.get('x-agentcc-cost')} | {p}")The first prompt is miss; the rest are paraphrases above the 0.92 similarity threshold and come back as hit_semantic with near-zero cost.
Tip
Tune the threshold carefully. Too low (e.g., 0.7) and unrelated questions collide; too high (e.g., 0.99) and you only catch near-exact matches. Start at 0.92 and adjust based on your hit rate vs false-positive rate.
Measure the savings
Loop over a realistic mixed batch and tally cache hits, total cost, and latency.
import time
from collections import Counter
batch = [
"What is your return policy?",
"Can I return a product?",
"How do I get a refund?",
"What's the shipping cost?",
"How long does shipping take?",
"Do you ship internationally?",
] * 5 # 30 calls total
tally = Counter()
total_cost = 0.0
start = time.time()
for p in batch:
r = client.chat.completions.with_raw_response.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": p}],
)
tally[r.headers.get("x-agentcc-cache") or "miss"] += 1
total_cost += float(r.headers.get("x-agentcc-cost") or 0)
print(f"cache results: {tally}")
print(f"total cost: ${total_cost:.5f}")
print(f"wall time: {time.time() - start:.1f}s")Expect ~80% hits after the first pass over each unique question (hit_exact for byte-identical, hit_semantic for paraphrases). Compare the total cost against the same batch with caching disabled. That’s your savings.
Bypass or invalidate the cache when you need fresh answers
When you change a system prompt or want a fresh response for a specific call, send x-agentcc-cache-force-refresh: true on that request. The gateway skips the cache read but still writes the new response back, so subsequent calls hit the refreshed entry.
r = client.chat.completions.with_raw_response.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": "What is your return policy?"}],
extra_headers={"x-agentcc-cache-force-refresh": "true"},
)
print(f"forced refresh: {r.headers.get('x-agentcc-cache')}") # miss, then re-cachedFor a global wipe after a prompt-template update, route your traffic to a fresh namespace by setting x-agentcc-cache-namespace: support-v2 instead of support. The old cache stays available to anything still pointed at support.
You enabled exact then semantic caching in the dashboard, watched paraphrased prompts return cached responses with x-agentcc-cache: hit_semantic, and measured the cost drop on a realistic batch, without changing application code beyond pointing at the gateway.
Explore further
Questions & Discussion