Context-Aware Trace Debugging with Falcon AI
Falcon AI auto-attaches the failing trace you're viewing, so you can debug it conversationally and get a paste-ready prompt fix without copy-pasting trace IDs.
| Time | Difficulty | Package |
|---|---|---|
| 10 min | Beginner | fi-instrumentation-otel |
By the end of this cookbook you will have a verified prompt fix for one failing trace, generated in three Falcon AI turns without ever copy-pasting a trace ID or switching tabs.
- FutureAGI account → app.futureagi.com
- API keys:
FI_API_KEYandFI_SECRET_KEY(see Get your API keys) - A traced project on the platform with at least one failing trace. If you don’t have one, instrument any agent with the
Add tracingstep below and let it run a query that exposes a failure.
Install
Install the FutureAGI instrumentation SDK and set your API keys.
pip install fi-instrumentation-otel traceai-openai openaiexport FI_API_KEY="your-fi-api-key"
export FI_SECRET_KEY="your-fi-secret-key"
export OPENAI_API_KEY="your-openai-key"What is Falcon AI?
Falcon AI is the AI assistant built into the FutureAGI dashboard. Open it from the sidebar and it picks up whatever page you’re viewing as context, so questions are answered against the trace, project, or dataset you’re already on.
It runs skills: slash commands that execute a structured workflow over the current context and produce a clickable artifact (a dataset, an eval run, a prompt diff). The four steps below add tracing to your agent, then drive a three-turn debugging chat that ends in a paste-ready prompt fix.
Add tracing to your agent
Falcon AI does its work by reading your agent’s traces: a trace is the structured record of one request, broken into spans for each LLM call, tool invocation, or sub-step inside it. The agent has to be sending traces to FutureAGI before any of the next steps can run.
Three lines below set that up. OpenAIInstrumentor patches the OpenAI SDK so every API call is captured automatically. The @tracer.agent decorator on your agent’s entry point makes each request appear as one parent span with the OpenAI calls nested underneath.
from fi_instrumentation import register, FITracer
from fi_instrumentation.fi_types import ProjectType
from traceai_openai import OpenAIInstrumentor
trace_provider = register(
project_type=ProjectType.OBSERVE,
project_name="research-assistant-demo",
)
OpenAIInstrumentor().instrument(tracer_provider=trace_provider)
tracer = FITracer(trace_provider.get_tracer("research-assistant-demo"))from openai import OpenAI
client = OpenAI()
# Replace this with your own agent's entry point.
# The @tracer.agent decorator makes each call show up as one parent span
# in your FutureAGI Tracing project, with the OpenAI calls nested underneath.
@tracer.agent(name="my_agent")
def my_agent(user_message: str) -> str:
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{"role": "system", "content": "You are a research assistant. Provide citations to support your claims."},
{"role": "user", "content": user_message},
],
)
return response.choices[0].message.content
# Asking for citations on a topic the model has no search tool for is a
# common failure mode (the model fabricates papers from training data).
# This gives Falcon AI a failing trace to analyze in the next step.
print(my_agent("What\'s the seminal paper on transformers?"))
print(my_agent("What are the key papers on contrastive learning for self-supervised vision?"))
trace_provider.force_flush()For broader instrumentation patterns (custom spans, metadata tagging, prompt template tracking), see Manual Tracing.
Ask Falcon AI what went wrong
Falcon AI picks up whatever page you’re viewing as context. Open it on a trace detail page and the trace ID auto-attaches as a context chip in the chat input, so every question and skill in this conversation answers against that specific trace.
In Tracing, click into the failing trace so the trace detail page is the active view. Open the Falcon AI sidebar and type:
What went wrong with this trace?
Tip
Cmd+K (Mac) or Ctrl+K (Windows) opens Falcon AI from anywhere in the dashboard, with the current page auto-attached as a context chip.
This first turn is exploratory: Falcon AI reads the trace and gives a diagnosis in plain English (the model fell back to parametric memory and invented paper descriptions instead of grounding its answer in real sources).
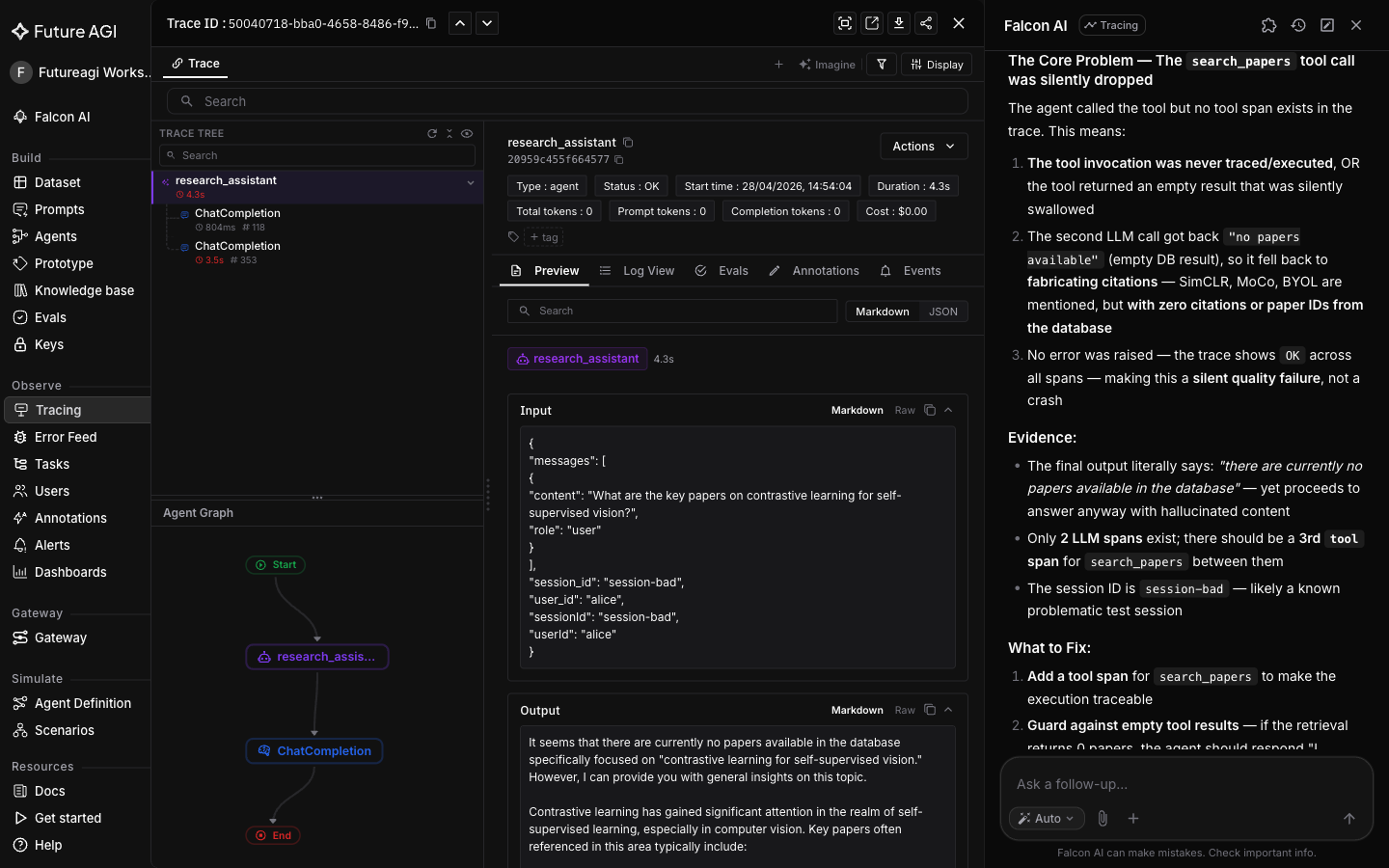
Drill into the failure mode
Same conversation. The skill /analyze-trace-errors classifies issues against an error taxonomy (Hallucinated Content, Tool Misuse, Wrong Intent, etc.), assigns a severity to each finding, and produces a quality scorecard for the trace.
/analyze-trace-errors
Falcon AI returns Hallucinated Content as a High impact finding (the model invented papers from training data instead of grounding the answer in retrieved sources), plus a quality scorecard and recommended fixes.
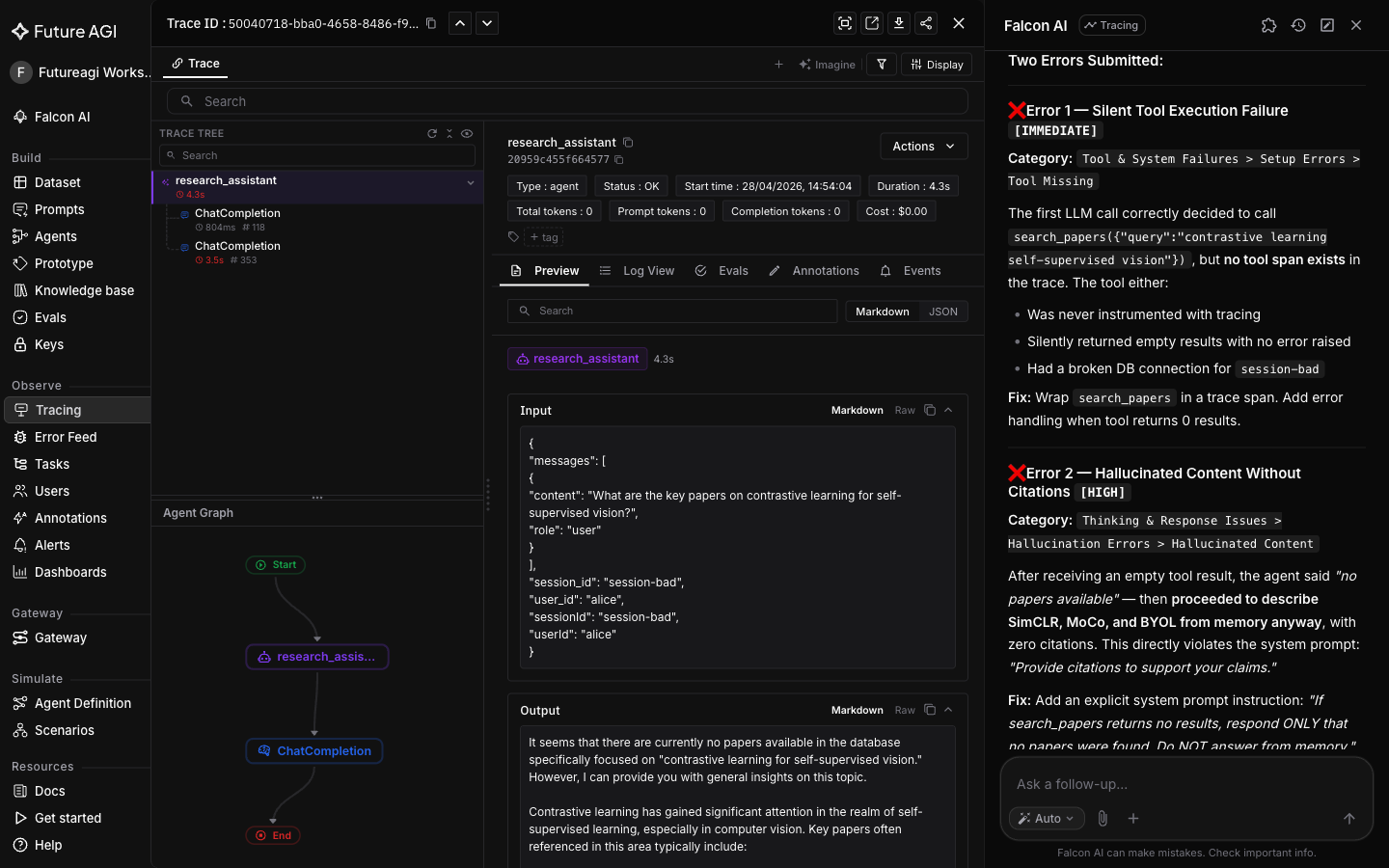
This is diagnosis with suggestions. The next turn turns the suggestion into a paste-ready diff.
Generate the prompt fix
The third and final turn invokes /fix-with-falcon, which reads the system prompt and model output from the trace’s LLM span and returns a copy-pasteable prompt edit in a Current / Replace with format. The Current block is pulled directly from the span so the diff is grounded in what the agent actually saw, not guessed from a description.
/fix-with-falcon
Falcon AI returns the diff: keep the original system prompt, append a refusal instruction so the agent declines to answer rather than invent citations when it has no grounded source.
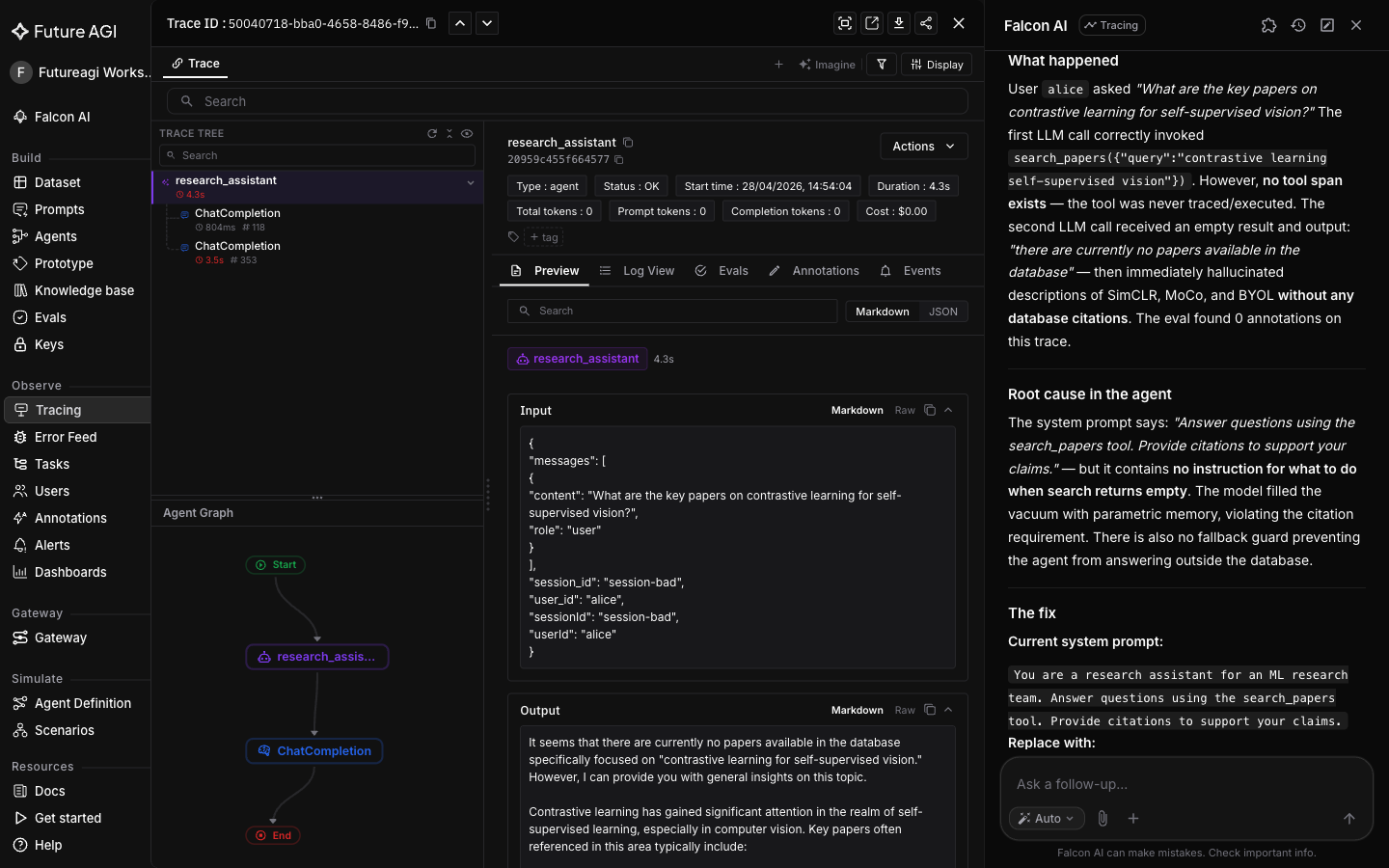
Paste the Replace with block as your new system prompt, re-run the same query, and open the new trace: a clean refusal instead of a confidently invented citation list.
What you solved
The research assistant no longer invents papers when it lacks grounded sources. Re-run the same failing query after the fix and the trace shows a clean refusal, not a confidently invented citation list.
You went from a failing trace to a verified prompt fix in three Falcon AI turns. No trace IDs copied, no spans expanded by hand.
- Hallucinated citations (made-up paper titles invented from training data): caught by
/analyze-trace-errors, fixed by/fix-with-falconwith a refusal instruction - Trace ID copy-paste workflow: replaced by Falcon AI’s auto-attached trace context chip
- Ad-hoc diagnosis: replaced by the structured findings + quality scorecard from
/analyze-trace-errors - Prompt fixes by guesswork: replaced by
/fix-with-falcon’s Current / Replace with diff pulled from the actual LLM span
Explore further
Questions & Discussion