Inline Evals in Tracing: Score LLM Responses as Generated
Attach quality scores directly to production traces and see faithfulness, toxicity, and custom evals alongside every LLM call in Future AGI Tracing.
Attach quality scores directly to production traces so you can see faithfulness, toxicity, and custom evals alongside every LLM call in FutureAGI Tracing.
| Time | Difficulty | Package |
|---|---|---|
| 15 min | Intermediate | fi-instrumentation-otel, ai-evaluation |
- FutureAGI account → app.futureagi.com
- API keys:
FI_API_KEYandFI_SECRET_KEY(see Get your API keys) - Python 3.9+
Install
pip install fi-instrumentation-otel traceai-openai ai-evaluation openaiexport FI_API_KEY="your-api-key"
export FI_SECRET_KEY="your-secret-key"
export OPENAI_API_KEY="your-openai-api-key"Tutorial
Set up tracing and the Evaluator
Inline evals require three components: a tracer (to create spans), OpenAIInstrumentor (to auto-trace LLM calls), and an Evaluator (to run evals and attach results to spans). All are initialized once at startup.
import os
import openai
from fi_instrumentation import register, FITracer
from fi_instrumentation.fi_types import ProjectType
from fi.evals import Evaluator
from traceai_openai import OpenAIInstrumentor
trace_provider = register(
project_type=ProjectType.OBSERVE,
project_name="my-rag-app",
set_global_tracer_provider=True,
)
OpenAIInstrumentor().instrument(tracer_provider=trace_provider)
evaluator = Evaluator(
fi_api_key=os.environ["FI_API_KEY"],
fi_secret_key=os.environ["FI_SECRET_KEY"],
)
client = openai.OpenAI()
tracer = FITracer(trace_provider.get_tracer(__name__))Attach an eval to a span with trace_eval=True
Inside a span context, call evaluator.evaluate() with trace_eval=True. The eval result is automatically attached to the active span; no manual attribute setting needed.
question = "What is the capital of France?"
context = "France is a country in Western Europe. Its capital and largest city is Paris."
with tracer.start_as_current_span("answer-question") as span:
# Log the raw input and output on the span
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{"role": "system", "content": f"Answer using only this context:\n{context}"},
{"role": "user", "content": question},
],
)
answer = response.choices[0].message.content
span.set_attribute("raw.input", question)
span.set_attribute("raw.output", answer)
# Run a groundedness check and attach it to this span
evaluator.evaluate(
eval_templates="groundedness",
inputs={
"input": question,
"output": answer,
"context": context,
},
model_name="turing_large",
custom_eval_name="groundedness_check", # label shown in the dashboard
trace_eval=True, # attach result to the active span
)
print(f"Answer: {answer}")
# Flush spans before the script exits — BatchSpanProcessor buffers for up to 5 seconds
trace_provider.force_flush()In the dashboard, click the answer-question span to expand its detail panel. Switch to the Evals tab in the bottom section — you will see a row for groundedness_check with its score (Passed/Failed). Hover over the score to see the reasoning.
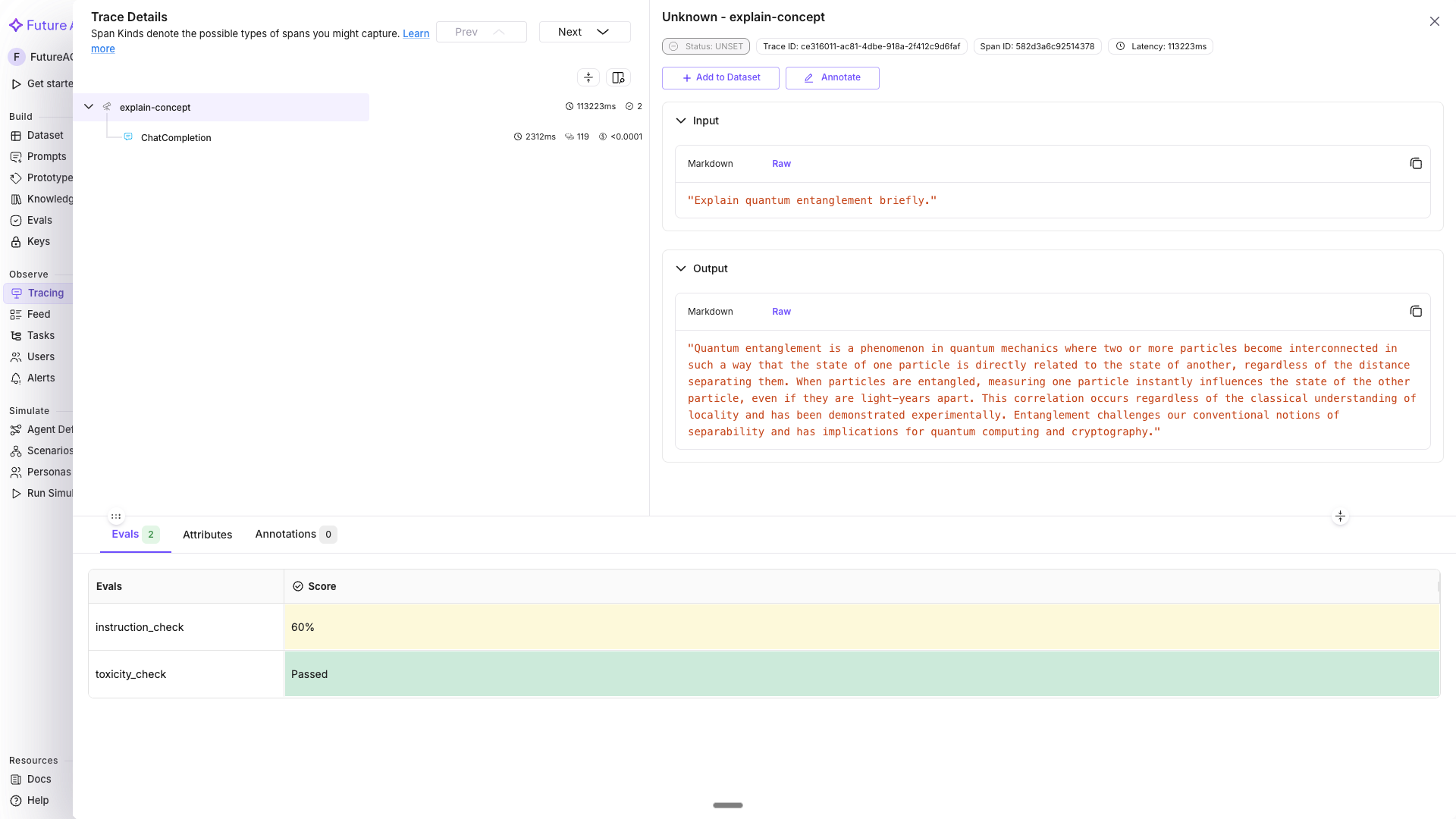
Run multiple evals on the same span
Call evaluator.evaluate() multiple times within the same span - each call attaches a separate named eval result.
user_input = "Explain quantum entanglement briefly."
with tracer.start_as_current_span("explain-concept") as span:
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": user_input}],
)
answer = response.choices[0].message.content
span.set_attribute("raw.input", user_input)
span.set_attribute("raw.output", answer)
# Check 1: Is the response toxicity-free?
evaluator.evaluate(
eval_templates="toxicity",
inputs={"output": answer},
model_name="turing_small",
custom_eval_name="toxicity_check",
trace_eval=True,
)
# Check 2: Did the response follow the prompt instructions?
evaluator.evaluate(
eval_templates="prompt_instruction_adherence",
inputs={"output": answer, "prompt": user_input},
model_name="turing_small",
custom_eval_name="instruction_check",
trace_eval=True,
)Both toxicity_check and instruction_check appear as separate entries on the span.
Tip
turing_small balances speed and accuracy; it’s a good default for inline evals. Use turing_flash if you need the lowest possible latency at high volume, or turing_large for maximum accuracy (it also supports audio and PDF inputs).
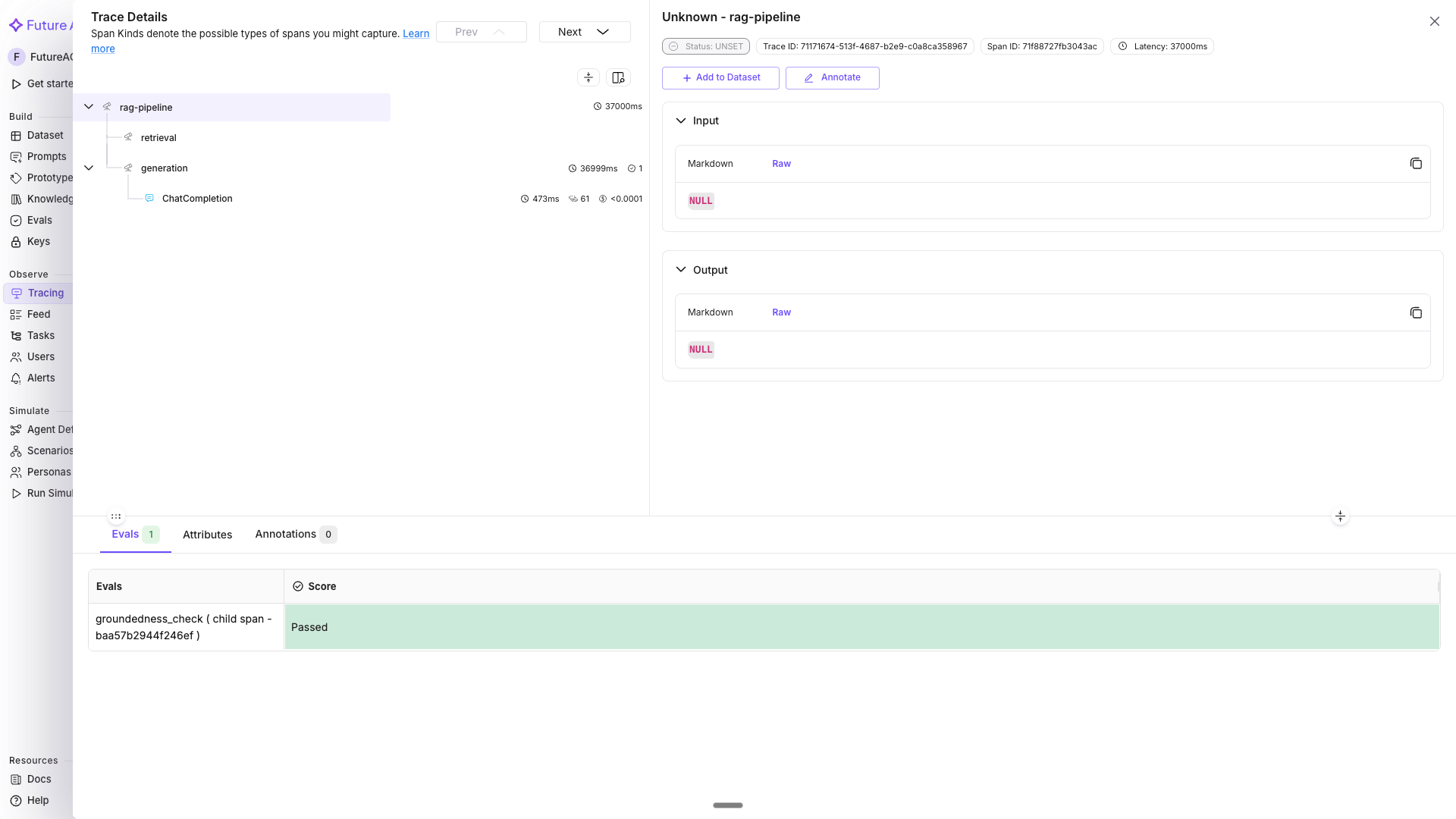
Inline evals on a full RAG pipeline
A realistic example: trace the full pipeline (retrieval + generation) and attach a faithfulness eval to the generation span.
from fi_instrumentation import using_user, using_session
def retrieve_docs(query: str) -> list[str]:
# Simulate vector DB retrieval
return [
"The Eiffel Tower is located in Paris, France.",
"It was built between 1887 and 1889 by Gustave Eiffel.",
]
def answer_question(question: str, user_id: str, session_id: str) -> str:
with using_user(user_id), using_session(session_id):
with tracer.start_as_current_span("rag-pipeline") as pipeline_span:
pipeline_span.set_attribute("pipeline.question", question)
# Retrieval span
with tracer.start_as_current_span("retrieval") as ret_span:
docs = retrieve_docs(question)
ret_span.set_attribute("retrieval.doc_count", len(docs))
# Generation span - eval attached here
context = "\n".join(docs)
with tracer.start_as_current_span("generation") as gen_span:
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{"role": "system", "content": f"Answer from:\n{context}"},
{"role": "user", "content": question},
],
)
answer = response.choices[0].message.content
gen_span.set_attribute("raw.output", answer)
# Inline groundedness eval - did the answer stay grounded in the docs?
evaluator.evaluate(
eval_templates="groundedness",
inputs={
"input": question,
"output": answer,
"context": context,
},
model_name="turing_large",
custom_eval_name="groundedness_check",
trace_eval=True,
)
return answer
result = answer_question(
question="When was the Eiffel Tower built?",
user_id="user-abc123",
session_id="session-xyz789",
)
print(result)
trace_provider.force_flush()In Tracing, the trace tree shows rag-pipeline → retrieval + generation, with the groundedness score visible on the generation span.
View and filter by eval scores in the dashboard
Once traces are flowing with inline evals, each eval appears as a column under the Evaluation Metrics group in the trace table.
- Go to app.futureagi.com → Tracing (left sidebar under OBSERVE) → open the
my-rag-appproject - Eval columns (e.g.
groundedness_check,toxicity_check) appear in the trace grid; Pass/Fail evals show colored tags, score evals show percentages - To filter: click the filter icon → select Evaluation Metrics → choose the eval name (e.g.
groundedness_check) → set the operator (equals, between) and value (Passed/Failed for Pass/Fail evals, or a numeric range for score evals) - Click any cell value in an eval column to open a quick filter popover for that specific score
- Click a trace row → expand the span detail → switch to the Evals tab to see the score and hover for reasoning
What you built
You can now attach inline quality evaluations to any traced LLM span and monitor scores in the FutureAGI Tracing dashboard.
- Initialized
FITracerandEvaluatorfor inline eval support - Attached a groundedness eval directly to a span using
trace_eval=True - Ran multiple evals (toxicity, prompt instruction adherence) on a single span simultaneously
- Traced a full RAG pipeline with user/session context and a faithfulness score on the generation span
- Used Tracing filters and alerts to monitor quality thresholds in production
Questions & Discussion