Prompt Versioning: Create, Label, and Serve Prompt Versions
Create prompt templates, commit numbered versions, assign labels like production, and serve the right version at runtime via SDK or dashboard.
Prompt Versioning lets you create prompt templates, commit numbered versions, assign labels (e.g. production), and serve the right version at runtime — all through the SDK and dashboard.
| Time | Difficulty | Package |
|---|---|---|
| 15 min | Beginner | futureagi + ai-evaluation |
- FutureAGI account → app.futureagi.com
- API keys:
FI_API_KEYandFI_SECRET_KEY(see Get your API keys) - Python 3.9+
Install
pip install futureagi ai-evaluation litellmexport FI_API_KEY="your-api-key"
export FI_SECRET_KEY="your-secret-key"Tutorial
Create a prompt via SDK
import os
from fi.prompt import Prompt
from fi.prompt.types import PromptTemplate, SystemMessage, UserMessage, ModelConfig
prompt_client = Prompt(
template=PromptTemplate(
name="support-response",
messages=[
SystemMessage(
content="You are a helpful customer support agent for TechStore. "
"Answer the customer's question clearly and professionally."
),
UserMessage(
content="Customer question: {{question}}"
),
],
model_configuration=ModelConfig(
model_name="gpt-4o-mini",
temperature=0.7,
max_tokens=1000,
),
),
fi_api_key=os.environ["FI_API_KEY"],
fi_secret_key=os.environ["FI_SECRET_KEY"],
)
# Create the prompt as a draft and commit it as v1
prompt_client.create()
prompt_client.commit_current_version(
message="Initial support prompt",
label="production",
)
print(f"Created: {prompt_client.template.name} ({prompt_client.template.version})")Expected output:
Created: support-response (v1)You can verify in the dashboard: Prompts (left sidebar) → open support-response → click the version chip → the Versions panel shows v1 with the production label.
Serve the prompt in your application
import os
import litellm
from fi.prompt import Prompt
def answer_question(question: str) -> str:
prompt = Prompt.get_template_by_name(
name="support-response",
label="production",
fi_api_key=os.environ["FI_API_KEY"],
fi_secret_key=os.environ["FI_SECRET_KEY"],
)
# compile() returns a list of message dicts; pass to any LLM
messages = prompt.compile(question=question)
response = litellm.completion(
model="gpt-4o-mini", # swap for any litellm-supported model
messages=messages,
)
return response.choices[0].message.content
print(answer_question("What is your return policy?"))Tip
compile() returns standard [{"role": "system", "content": "..."}, ...] message dicts — compatible with any LLM provider via litellm. Use "groq/llama-3.3-70b-versatile", "anthropic/claude-sonnet-4-20250514", or any other litellm-supported model.
Create v2 with chain-of-thought reasoning
Each version can have its own model configuration. Here v2 uses a lower temperature for more deterministic chain-of-thought responses.
from fi.prompt.types import PromptTemplate, SystemMessage, UserMessage, ModelConfig
# Create a new version with updated messages and model config
prompt_client.create_new_version(
template=PromptTemplate(
name="support-response",
messages=[
SystemMessage(
content="You are a precise customer support agent for TechStore.\n\n"
"Think through the customer's question step by step before answering:\n"
"1. What is the customer asking?\n"
"2. What information do I have that directly addresses this?\n"
"3. What is the clearest, most helpful response?"
),
UserMessage(
content="Customer question: {{question}}\n\nAnswer:"
),
],
model_configuration=ModelConfig(
model_name="gpt-4o-mini",
temperature=0.3,
max_tokens=1000,
),
),
commit_message="Add chain-of-thought reasoning",
)
# Save and commit v2
prompt_client.save_current_draft()
prompt_client.commit_current_version(message="v2: chain-of-thought prompt")
print(f"v2 created: {prompt_client.template.version}")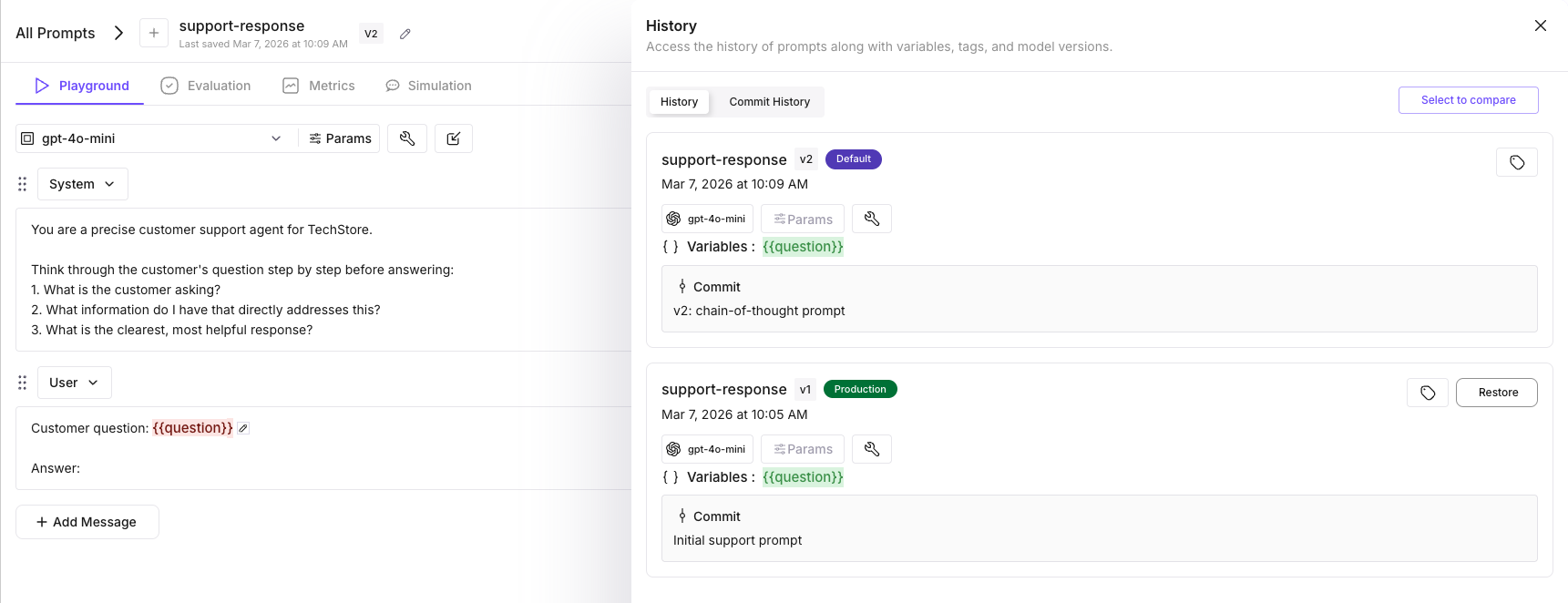
Test v2 before promoting it
We use is_concise here — for a support agent, concise answers are a key quality signal. You can swap in any of the 72+ built-in eval metrics like groundedness, tone, completeness, or instruction_adherence depending on what you want to measure.
import litellm
from fi.evals import evaluate
test_cases = [
"What is your return policy?",
"How long does standard shipping take?",
"Can I exchange a product instead of returning it?",
]
# Fetch v2 by version number
v2_prompt = Prompt.get_template_by_name(
name="support-response",
version="v2",
fi_api_key=os.environ["FI_API_KEY"],
fi_secret_key=os.environ["FI_SECRET_KEY"],
)
print(f"{'Question':<45} {'Concise':>8}")
print("-" * 55)
for question in test_cases:
messages = v2_prompt.compile(question=question)
response = litellm.completion(
model="gpt-4o-mini",
messages=messages,
)
output = response.choices[0].message.content
result = evaluate(
"is_concise",
output=output,
model="turing_small",
)
print(f"{question[:43]:<45} {result.score:>8}")Expected output:
Question Concise
-------------------------------------------------------
What is your return policy? True
How long does standard shipping take? True
Can I exchange a product instead of retur TruePromote v2 to production
Prompt.assign_label_to_template_version(
template_name="support-response",
version="v2",
label="production",
fi_api_key=os.environ["FI_API_KEY"],
fi_secret_key=os.environ["FI_SECRET_KEY"],
)
print("v2 is now live in production.")Your application now serves v2 on the next request — no redeploy. The get_template_by_name(label="production") call in Step 2 automatically picks up the new version.
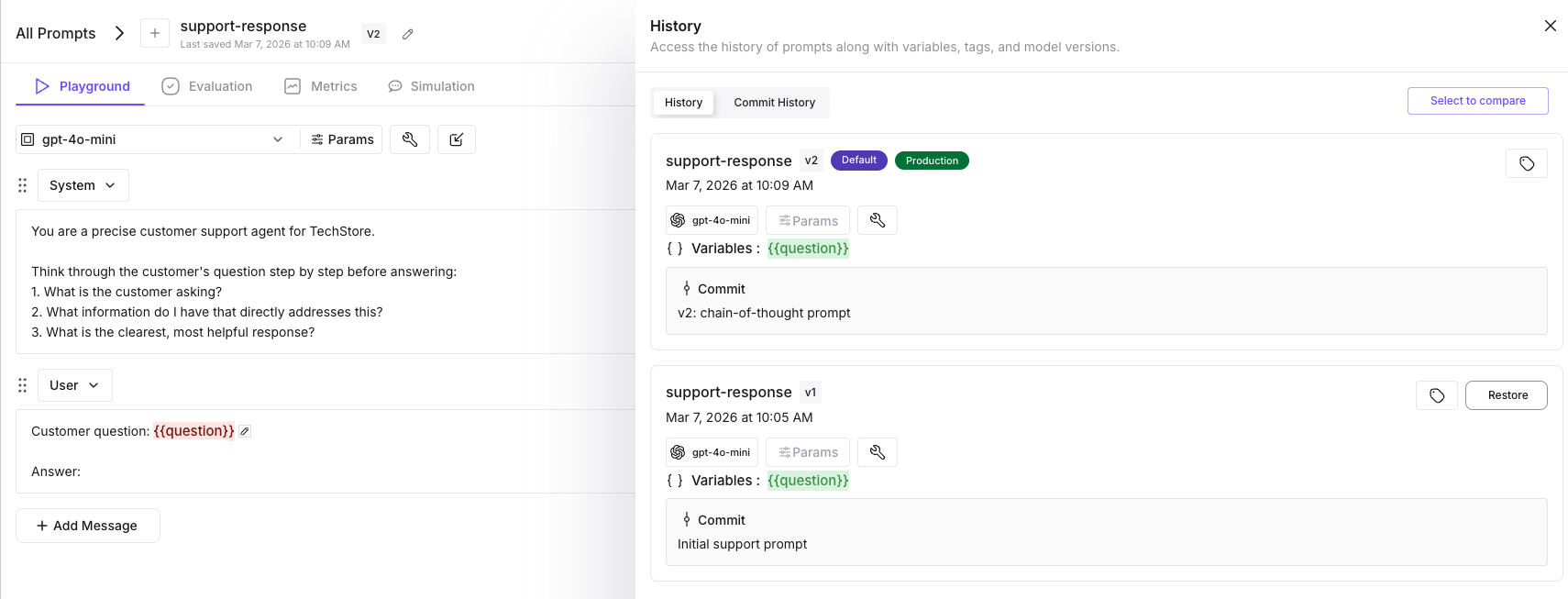
Rollback to v1
If v2 causes issues, reassign the production label back to v1. Your app picks up the change on the next request.
Prompt.assign_label_to_template_version(
template_name="support-response",
version="v1",
label="production",
fi_api_key=os.environ["FI_API_KEY"],
fi_secret_key=os.environ["FI_SECRET_KEY"],
)
print("Rolled back to v1.")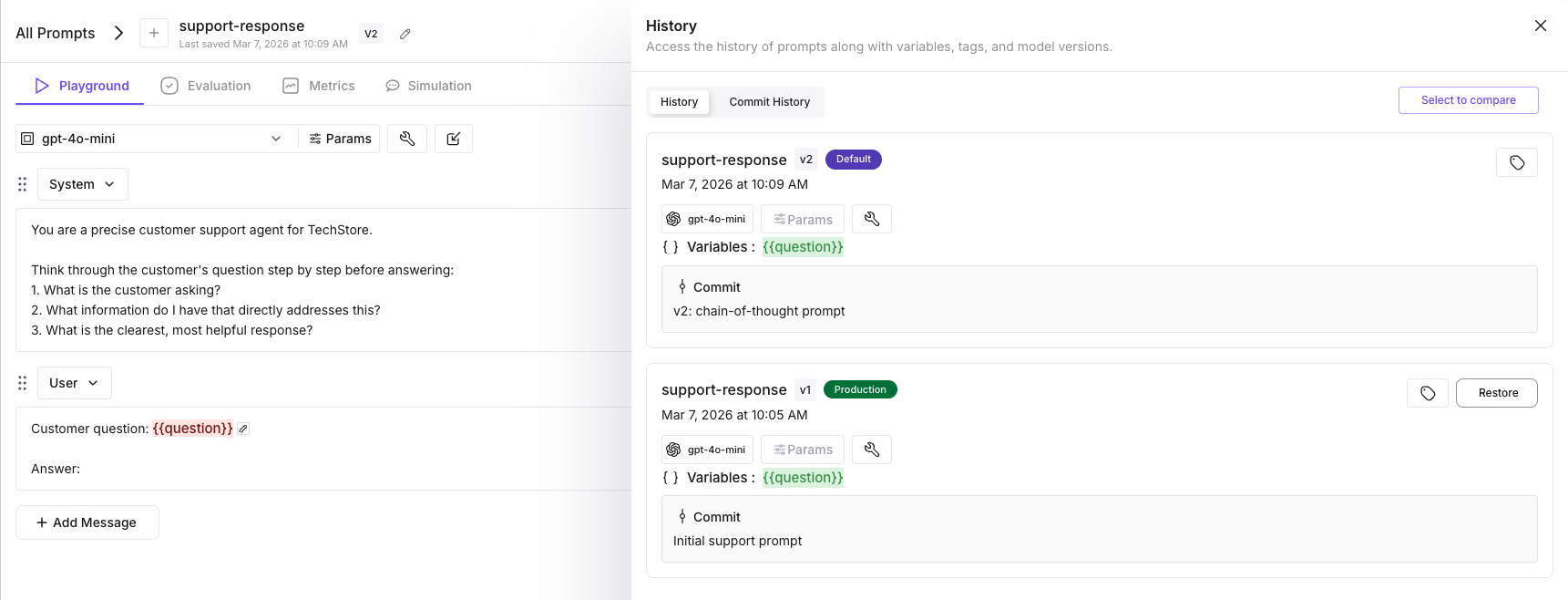
View version history
versions = prompt_client.list_template_versions()
for v in versions:
draft = "draft" if v.get("isDraft") else "committed"
print(f" {v['templateVersion']} {draft} {v['createdAt']}")Expected output:
v2 committed 2026-03-06T14:40:00Z
v1 committed 2026-03-06T14:35:00ZAlternative: Create and iterate from the dashboard
You can also create and version prompts entirely from the dashboard.
Create v1:
- Go to app.futureagi.com → Prompts (left sidebar) → Create Prompt
- Select Write a prompt from scratch
- Click the pencil icon next to the prompt name — type
support-responseand press Enter - Click Select Model and choose a model (e.g.
gpt-4o-mini) - Write the system and user messages
- Click Run Prompt (top-right) — the prompt runs, generates output, and saves as v1
Create v2:
- Edit the system and user messages in the prompt editor
- Click Run Prompt — editing and running automatically creates a new version (v2)
- Click the version chip (e.g. “V2”) to see both v1 and v2 in the Versions panel
Label management is SDK-only — use assign_label_to_template_version() (Step 5 above) to assign production/staging labels to any version.
Prompt SDK reference
| Method | Description |
|---|---|
Prompt(template=PromptTemplate(...)).create() | Create a new prompt as a draft |
commit_current_version(message, label) | Commit draft and optionally assign a label |
create_new_version(template, commit_message) | Commit current draft, then create a new draft version |
save_current_draft() | Push in-memory changes to the backend draft |
get_template_by_name(name, label, version) | Fetch a prompt by name + label or version number |
compile(**kwargs) | Render messages with variable substitution |
list_template_versions() | List all versions with draft status and timestamps |
assign_label_to_template_version(template_name, version, label) | Assign a label to a specific version |
remove_label_from_template_version(template_name, version, label) | Remove a label from a version |
set_default_version(template_name, version) | Set which version is returned when no label/version is specified |
delete() | Delete the prompt template |
What you built
You can now version, evaluate, promote, and roll back prompts via SDK without redeploying application code.
- Created a
support-responseprompt via SDK and committed v1 with the production label - Served the prompt in your app via
get_template_by_name(label="production")+compile()with litellm - Created v2 with chain-of-thought reasoning and a different
ModelConfig(lower temperature) - Evaluated v2 against test cases before promoting it
- Promoted v2 to production — your app picks it up on the next request, zero-downtime
- Rolled back to v1 by reassigning the production label
- Viewed version history with
list_template_versions()
Questions & Discussion