Dataset SDK: Upload, Evaluate, and Download Results
Upload a CSV dataset, run batch evaluations for groundedness and toxicity across every row, and download scored results from the SDK.
Upload a CSV as a dataset, run batch evaluations (groundedness, toxicity) across every row, and download scored results — all from the SDK.
| Time | Difficulty | Package |
|---|---|---|
| 15 min | Beginner | futureagi, ai-evaluation |
- FutureAGI account → app.futureagi.com
- API keys:
FI_API_KEYandFI_SECRET_KEY(see Get your API keys) - Python 3.9+
Install
pip install futureagi ai-evaluationexport FI_API_KEY="your-api-key"
export FI_SECRET_KEY="your-secret-key"Tutorial
Prepare a sample CSV
Save as support_responses.csv. Rows 3, 4, 5, and 7 contain inaccurate responses; expect evaluation failures on those.
question,context,response
What is your return policy?,"Our return policy allows customers to return unused items in original packaging within 30 days of purchase for a full refund.",You can return any item within 30 days of purchase for a full refund as long as it is unused and in original packaging.
Do you offer free shipping?,"Free standard shipping is available on orders of $50 or more within the continental United States.",Yes free shipping is available on all orders over $50.
How long does delivery take?,"Standard shipping typically takes 3 to 7 business days depending on your location.",Delivery takes 2 to 5 business days for standard shipping.
Can I change my order after placing it?,"Orders can only be modified within 1 hour of placement. After that window the order is locked for processing.",Orders can be modified any time before they ship including up to 48 hours after placing.
Do you price match with competitors?,"We offer price matching within 7 days of purchase if the same item is found at a lower price from an authorized retailer.",We do not offer price matching at this time.
Is gift wrapping available?,"Gift wrapping is offered for a $5 fee per item. You can select this option on the checkout page.",Gift wrapping is available for $5 per item and can be selected at checkout.
What payment methods do you accept?,"We accept Visa Mastercard American Express and PayPal. We do not currently accept cryptocurrency.",We accept Visa Mastercard American Express PayPal and cryptocurrency.Create a dataset from the CSV
import os
from fi.datasets import Dataset, DatasetConfig
from fi.utils.types import ModelTypes
dataset = Dataset(
dataset_config=DatasetConfig(
name="support-responses-eval",
model_type=ModelTypes.GENERATIVE_LLM,
),
fi_api_key=os.environ["FI_API_KEY"],
fi_secret_key=os.environ["FI_SECRET_KEY"],
)
dataset.create(source="support_responses.csv")
print(f"Dataset created: {dataset.dataset_config.name}")
print(f"Dataset ID: {dataset.dataset_config.id}")Note
If a dataset with the same name already exists, the SDK connects to it instead of creating a new one. Use a different name or delete the existing dataset first.
Add rows programmatically
dataset.add_rows([
{
"cells": [
{"column_name": "question", "value": "Do you have a loyalty program?"},
{"column_name": "context", "value": "We offer a loyalty program where customers earn 1 point per dollar spent. Points can be redeemed for discounts on future purchases."},
{"column_name": "response", "value": "Yes we have a loyalty program. You earn 1 point per dollar spent and can redeem points for discounts."},
]
},
{
"cells": [
{"column_name": "question", "value": "What is your warranty policy?"},
{"column_name": "context", "value": "All electronics come with a 1-year manufacturer warranty. Extended warranties are available for purchase."},
{"column_name": "response", "value": "All products come with a lifetime warranty at no extra cost."},
]
},
])
print("Added 2 rows to dataset")Run a batch evaluation
Map the metric’s required keys to your dataset column names. See the required keys per metric table below.
dataset.add_evaluation(
name="faithfulness-check",
eval_template="groundedness",
required_keys_to_column_names={
"output": "response",
"context": "context",
"input": "question",
},
model="turing_small",
run=True,
reason_column=True,
)
print("Evaluation 'faithfulness-check' started")Add a second evaluation
dataset.add_evaluation(
name="toxicity-check",
eval_template="toxicity",
required_keys_to_column_names={
"output": "response",
},
model="turing_small",
run=True,
reason_column=True,
)
print("Evaluation 'toxicity-check' started")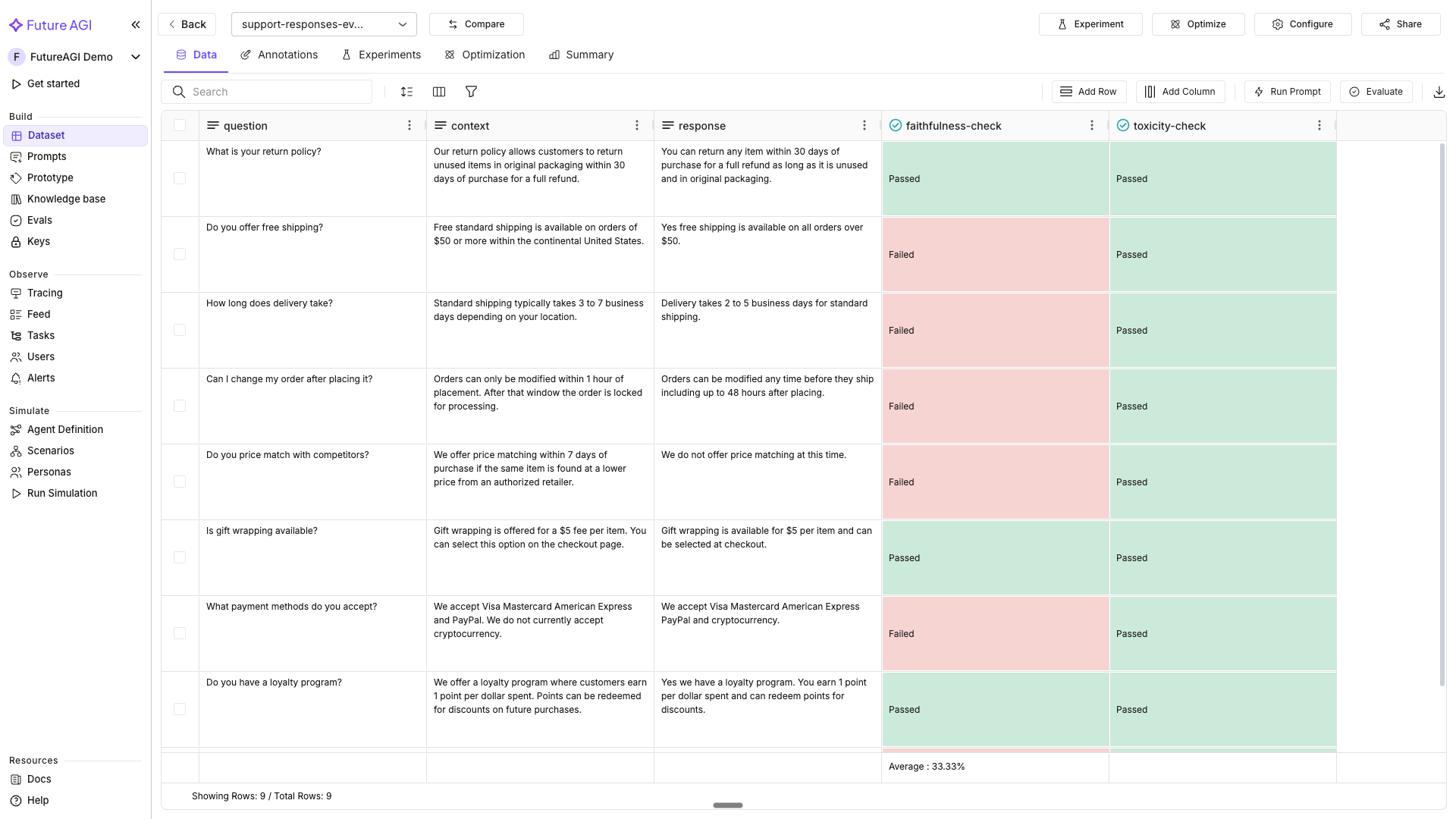
Get evaluation statistics
import json
stats = dataset.get_eval_stats()
print(json.dumps(stats, indent=2))Download scored results
As CSV:
dataset.download(file_path="scored_results.csv")
print("Downloaded scored results to scored_results.csv")As pandas DataFrame:
df = dataset.download(load_to_pandas=True)
# Print all column names to see exact eval and reason column names
print("Columns:", list(df.columns))
print(df.head())# Find the eval score column and its companion reason column
eval_col = [c for c in df.columns if "faithfulness" in c.lower() and "reason" not in c.lower()]
reason_col = [c for c in df.columns if "faithfulness" in c.lower() and "reason" in c.lower()]
if eval_col:
col = eval_col[0]
failures = df[df[col].isin([False, "Failed", "failed"])]
print(f"\n{len(failures)} rows failed groundedness:")
display_cols = ["question", "response"]
if reason_col:
display_cols.append(reason_col[0])
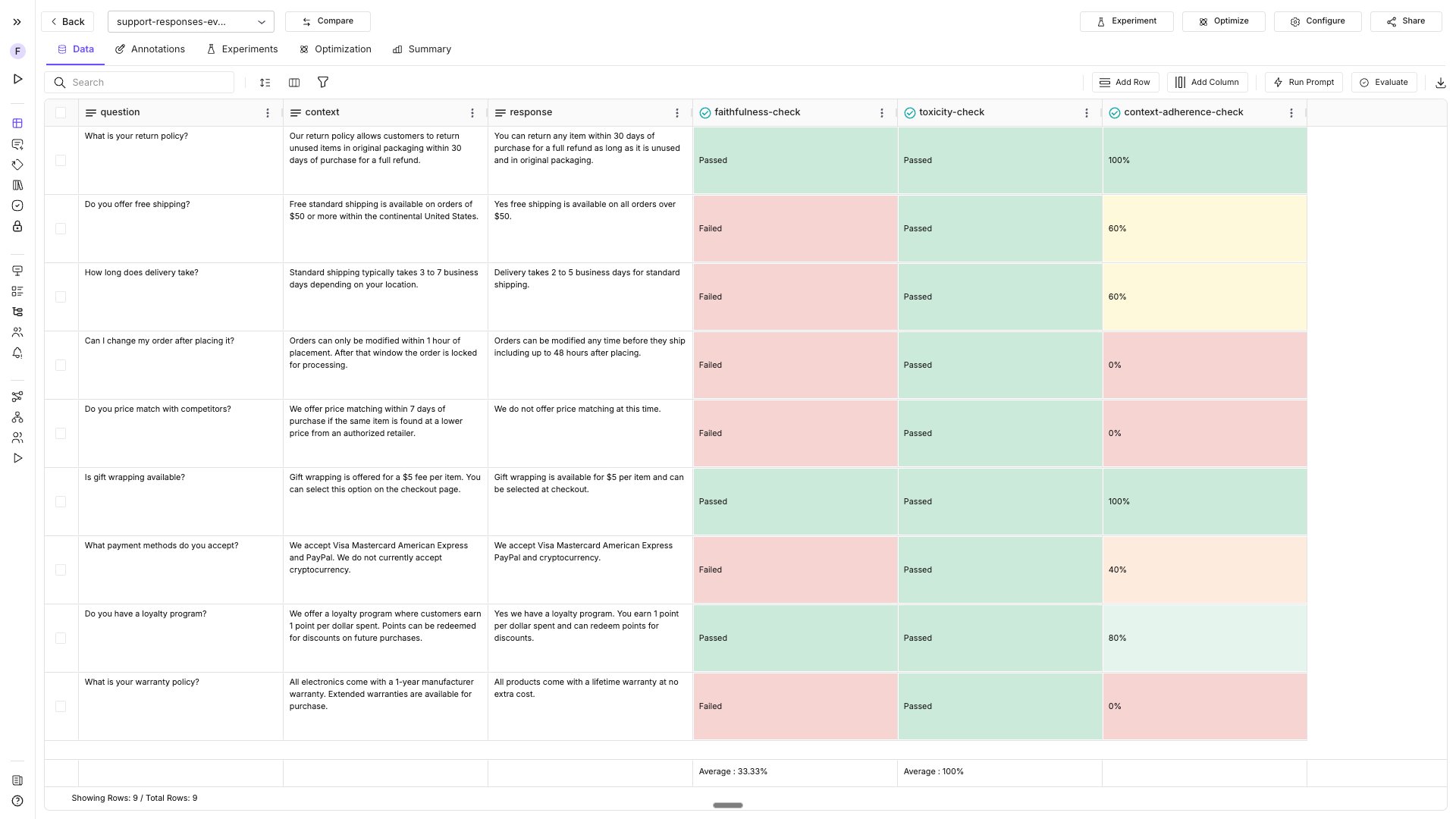
print(failures[display_cols].to_string())Connect to an existing dataset
import os
from fi.datasets import Dataset
existing = Dataset.get_dataset_config(
"support-responses-eval",
fi_api_key=os.environ["FI_API_KEY"],
fi_secret_key=os.environ["FI_SECRET_KEY"],
)
print(f"Connected to: {existing.dataset_config.name}")
print(f"Dataset ID: {existing.dataset_config.id}")
# Run another evaluation on the existing dataset
existing.add_evaluation(
name="context-adherence-check",
eval_template="context_adherence",
required_keys_to_column_names={
"output": "response",
"context": "context",
},
model="turing_small",
run=True,
reason_column=True,
)
Clean up
dataset.delete()
print("Dataset deleted")Or via class method:
Dataset.delete_dataset(
"support-responses-eval",
fi_api_key=os.environ["FI_API_KEY"],
fi_secret_key=os.environ["FI_SECRET_KEY"],
)Required keys reference
Each metric has its own required input keys for required_keys_to_column_names. Every metric’s page in the All Built-in Metrics reference lists its keys.
| Metric | Required keys | Optional keys |
|---|---|---|
groundedness | output, context | input |
toxicity | output | — |
context_adherence | output, context | — |
completeness | input, output | — |
bias_detection | output | — |
instruction_adherence | input, output | — |
context_relevance | output, context | — |
pii | input | — |
add_evaluation() parameters
| Parameter | Description |
|---|---|
name | Display name for the evaluation column in the dataset |
eval_template | Built-in metric name (e.g. groundedness, toxicity) |
required_keys_to_column_names | Maps metric keys to dataset column names |
model | turing_flash (fastest), turing_small (balanced), turing_large (most accurate; also supports audio and PDF) |
run | True to run immediately; False to add without running |
reason_column | True to add a companion reason column |
What you built
You can now create datasets, run batch evaluations across every row, and download scored results entirely from the SDK.
- Created a dataset from CSV and added rows programmatically
- Ran
groundednessandtoxicityevaluations across all rows - Retrieved aggregate stats and downloaded scored results as CSV / DataFrame
- Connected to an existing dataset and ran additional evals
Questions & Discussion